¡Bienvenidos al tercer post de Machine Learning del blog! En el vamos utilizar el algoritmo inteligente creado en el anterior post y vamos a importarlo en un aplicación Web en JAVA. Para terminar vamos a exponer un servicio REST al cual vamos a consultarlo para realizar predicciones. Así que ¡Manos a la obra!
Entrenarlo una única vez, deployarlo en donde sea
Este va a ser nuestro objetivo en este post. Tenemos un algoritmo entrenado en Python y vamos a usar el modelo creado en una aplicación web que tenemos en JAVA. Nuestro flujo sera el siguiente:
- Entrenamos un modelo en Python
- Exportamos el modelo a PMML
- Importamos el modelo PMML a una aplicación JAVA
Para ello usaremos el estándar PMML
¿Que es PMML?
PMML (Predictive Model Markup Language) es un estándar XML para representar modelos predictivos. Un archivo PMML contiene toda la información relacionada con el modelo, como el set de entrenamiento usado y el algoritmo elegido.
Dado que PMML es un estándar, la idea es que este archivo puede ser interpretado de la misma manera por diferentes tipos de lenguaje. De acá viene la frase que hemos usado anteriormente “Entrenarlo una única vez, deployarlo en donde sea”. Podemos construir un modelo en un ambiente con las herramientas necesarias (Python, Sklearn, MatplotLib) y deployarlo en otro ambiente (Una aplicación web en JAVA por ejemplo)
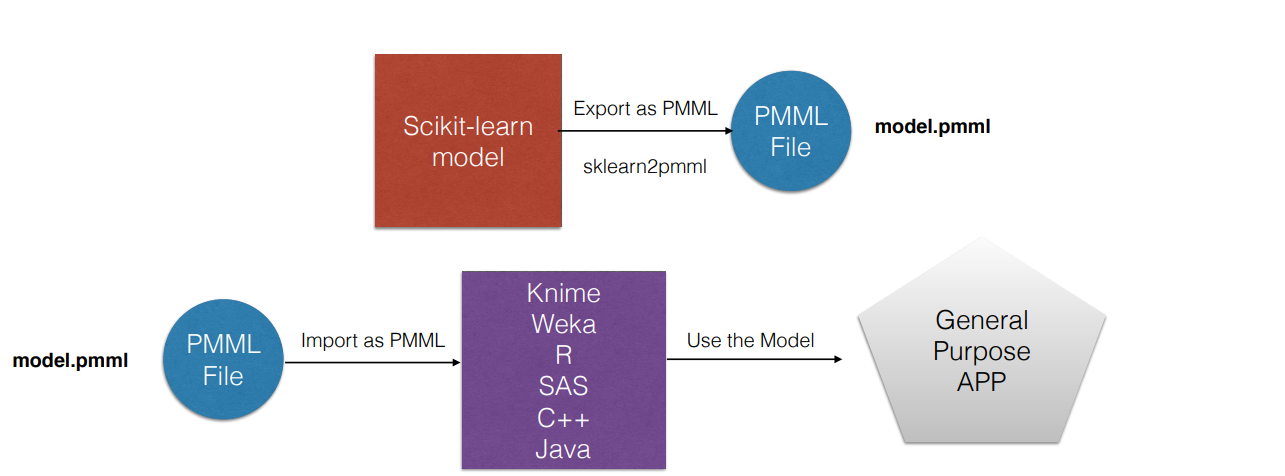
La idea detrás de PMML: entrenarlo en un ambiente con las herramientas necesarias, exportarlo y utilizarlo en nuestra app en el lenguaje favorito de todos
Recordando
Anteriormente usamos el set de datos de IRIS para crear un algoritmo inteligente el cual es capaz de predecir a qué tipo de especie pertenece una flor de IRIS de acuerdo a las dimensiones de sus pétalos. El algoritmo que utilizamos es KNN el cual, es uno de los más conocidos.
El código se encuentra en el siguiente repositorio:
Exportar el modelo a PMML
Una vez entrenado el modelo lo exportamos en un archivo PMML con la librería sklearn2-pmml. Con esto basta con ejecutar la siguientes líneas:
from sklearn2pmml.pipeline import PMMLPipeline
from sklearn2pmml import sklearn2pmml
pipeline = PMMLPipeline([("classifier", KNeighborsClassifier(n_neighbors=3))]) pipeline.fit(set_entrenamiento_caso_petalos_x,set_entrenamiento_caso_petalos_y)
sklearn2pmml(pipeline, "KNN.pmml", with_repr = True)Lo que estamos haciendo es crearnos un objeto PMMLPipeline asignando que vamos a usar un clasificador y el tipo de algoritmo.
Finalmente a este objeto le asignamos los set de datos de entrenamiento y lo exportamos a un archivo PMML
Importando el archivo en un proyecto
El proyecto que usaremos se encuentra en el siguiente repositorio:
https://gitlab.com/somospnt/techies/ejemplo-java-machine-learning-iris
El branch que usaremos en este ejemplo se llama “inicial”. En este mismo lo que tenemos creado es una clase ClasificadorEspecieRestController la cual usamos para exponer un endpoint. También tenemos creada un clase de configuración ModelConfiguration la cual se encarga de crear un modelo en base el archivo PMML y para finalizar tenemos una clase ClasificadorEspecieService la cual tendrá la lógica para obtener los resultados de la predicción.
Lo primero que hacemos es importar las dependencias de JPMML-Evaluator y JPMML-Model en el POM del proyecto y compilarlo
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-model</artifactId>
<version>1.4.10</version>
</dependency>
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator</artifactId>
<version>1.4.8</version>
</dependency>
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator-extension</artifactId>
<version>1.4.8</version>
</dependency>Con las dependencias instaladas, copiamos al classpath de la aplicación el archivo “KNN.pmml”. Luego creamos un bean en la clase de configuración de la siguiente forma:
@Bean
public Evaluator modelEvaluator() throws SAXException, JAXBException, IOException {
InputStream resource = new ClassPathResource("KNN.pmml").getInputStream();
PMML pmmlArchivo = PMMLUtil.unmarshal(resource);
ModelEvaluatorBuilder modelEvaluatorBuilder = new ModelEvaluatorBuilder(pmmlArchivo);
Evaluator evaluator = (Evaluator) modelEvaluatorBuilder.build();
return evaluator;
}La idea de este bean es crearnos un objeto Evaluator el cual usaremos para realizar las predicciones.
Lo primero que hacemos es importar el archivo KNN.pmml como un InputResource y crearse un objeto PMML que tiene toda la información del modelo. Luego de esto creamos un ModelEvaluatorBuilder usando PMML y finalmente creamos el objeto Evaluator.
Ahora modificamos el service implementando el método clasificarEspecie para usar el modelEvaluator para predecir el tipo de especie de IRIS a partir de las dimensiones de una flor
@Service
public class ClasificadorEspecieService {
@Autowired
private Evaluator modelEvaluator;
public String clasificarEspecie(BigDecimal longitudPetalo, BigDecimal anchoPetalo) {
Map<FieldName, FieldValue> argumentos = new LinkedHashMap<>();
FieldName fieldNameLongitud = FieldName.create("PetalLengthCm");
FieldName fieldNameAncho = FieldName.create("PetalWidthCm");
FieldValue fieldValueLongitud = FieldValue.create(TypeInfos.CATEGORICAL_FLOAT, longitudPetalo.floatValue());
FieldValue fieldValueAncho = FieldValue.create(TypeInfos.CATEGORICAL_FLOAT, anchoPetalo.floatValue());
argumentos.put(fieldNameLongitud, fieldValueLongitud);
argumentos.put(fieldNameAncho, fieldValueAncho);
Map<String, String> resultRecord = (Map<String, String>) EvaluatorUtil.decodeAll(modelEvaluator.evaluate(argumentos));
return resultRecord.get("Species");
}
}En este método lo que hacemos es crearnos 2 tipos de objetos: Un fieldName el cual tendrá el nombre del feature que definimos a la hora de entrenar el modelo y un fieldValue el cual tendrá el tipo y valor del feature. Por ejemplo: “PetalLengthCm” como nombre y el tipo es un float de valor 1.0 en nuestro caso
Finalmente los insertamos en un Map<FieldName, FieldValue> y los usamos para evaluarlos con el modelEvaluator con la función evaluate(), la cual es la encargada de realizar las predicciones en el modelo. Finalmente lo que hacemos es decodear el resultado en un Map y obtenerlo con la función get utilizando el nombre del label resultante, es decir, "Species".
¡Listo! Esto fue todo lo que teniamos que hacer. Corremos el proyecto y consultamos la siguiente url:
http://localhost:8080/clasificarEspecie?longitudPetalo=0.5&anchoPetalo=0.5
En esta url esta expuesto nuestro endpoint que recibe 2 parametros por la url: longitudPetalo y anchoPetalo. Nuestro RestController toma esos parametros, en el service predecimos el tipo de especie y la retornamos.
Analizando los resultados del algoritmo
Tenemos el algoritmo que predice.... ¿Y ahora? ¿Como se que predice correctamente?. Acá es donde cobra nuevamente importancia el análisis de los datos. Con el mismo pudimos encontrar el siguiente patrón:
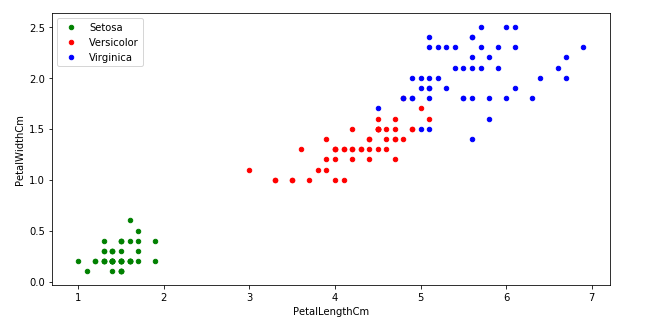
El ScatterPlot del post anterior. En el podemos observar que hay una relacion entre las dimensiones de petalos y el tipo de especie
El tipo de especie Setosa se diferencia del resto por su ancho y longitud menor al resto de las especies. Y la especie Virginica se caracteriza por tener ancho y longitud mayor al resto.
Con esta información podemos ver que resultados esperamos. Usando los siguiente parámetros tendríamos que tener la especie Setosa
http://localhost:8080/clasificarEspecie?longitudPetalo=0.5&anchoPetalo=0.5
Observamos que retorna la especie Setosa. Y con los siguiente parámetros esperamos que el resultado sea la especie Virginica:
http://localhost:8080/clasificarEspecie?longitudPetalo=7.0&anchoPetalo=2.5
Efectivamente es lo que esperabamos, por lo que podemos decir que el algoritmo “hace lo que esperamos que haga”.
Ahora que pasa si intento con algún punto no conocido? Por ejemplo longitud: 2.5 y ancho: 1.0.
http://localhost:8080/clasificarEspecie?longitudPetalo=2.5&anchoPetalo=1.0
El algoritmo predice que es la especie Versicolor. No es un punto que el conoce, es nuevo para el pero en base al entrenamiento que tuvo predice que ese será el tipo.
Conclusiones
En esta serie de post hemos aprendido qué es Machine Learning y Data Science, qué usos tiene en la actualidad y los diferentes tipos de algoritmos posibles juntos con sus tipos de problemas más comunes. Además hemos aprendido el gran valor que tiene el análisis previo del set de datos antes de sentarnos a implementar nuestro algoritmo. Para finalizar, hemos aprendido a exportar nuestro modelo a un archivo PMML e importarlo en un lenguaje como JAVA para poder utilizarlo en una aplicación web.
Esto no es todo lo que podemos hacer con Machine Learning, el resto queda en ustedes en investigar (¡O esperar próximos posts!)
¡Gracias por el espacio y espero que les haya gustado!