En el anterior post hemos aprendido los conceptos básicos de Machine Learning. Ahora ha llegado la hora de codear nuestro primer algoritmo. En este post mostraremos como realizar un hola mundo con Python y Jupyter, explicando cada paso. ¡Así que manos a la obra!
¿Porqué Python?
Sí, leíste bien, Python. Amamos Java pero le damos la bienvenida a Python como lenguaje a utilizar en Machine Learning. La principal ventaja radica en la enorme cantidad de librerías que tenemos a nuestra disposición. Para implementar el algoritmo usamos NumPy, SciPy, ScikitLearn, PyBrain; para realizar un análisis exploratorio de datos y graficar tenemos MatPlotLib, Seaborn; y para leer la información y procesarla utilizamos Pandas.

Las librerías más conocidas para Machine Learning en Python. NumPy, SciPy, MatPlotLib, Pandas y Scikit Learn
Nuestro ejemplo será muy sencillo de implementar si usamos Python y Jupyter.
¿Que es Jupyter?
Jupyter Notebook es un entorno de trabajo en el cual podemos agregar secciones de código de Python y correrlo de una manera dinámica y sencilla. Además permite ingresar bloques de texto e imágenes usando la sintaxis de Markdown lo que hace que quede como si fuera un documento. Dada esta sencillez se lo suele usar como una herramienta interactiva para el aprendizaje
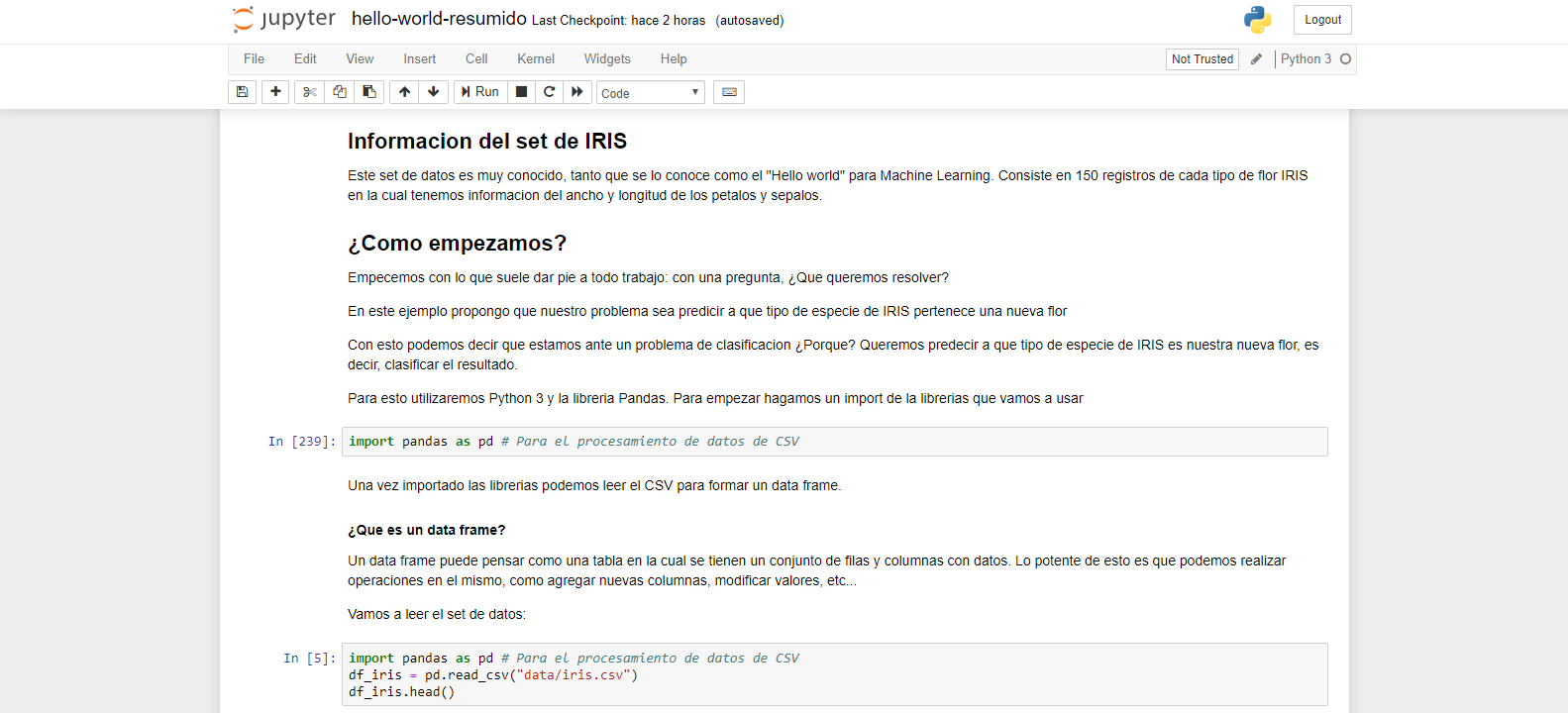
La interfaz de Jupyter. Podemos observar que combina la posibilidad de agregar bloques de código de python y texto como si fuera un documento
Preparando el ambiente de trabajo
Utilizaremos Anaconda, la cual es una distribución Open-Source de Python que incluye librerías pre-instaladas orientadas a Data Science (Gráficos, Exploración de Datos, Algoritmos). Una vez instalado basta con correr el módulo de Jupyter Notebook para empezar a trabajar.
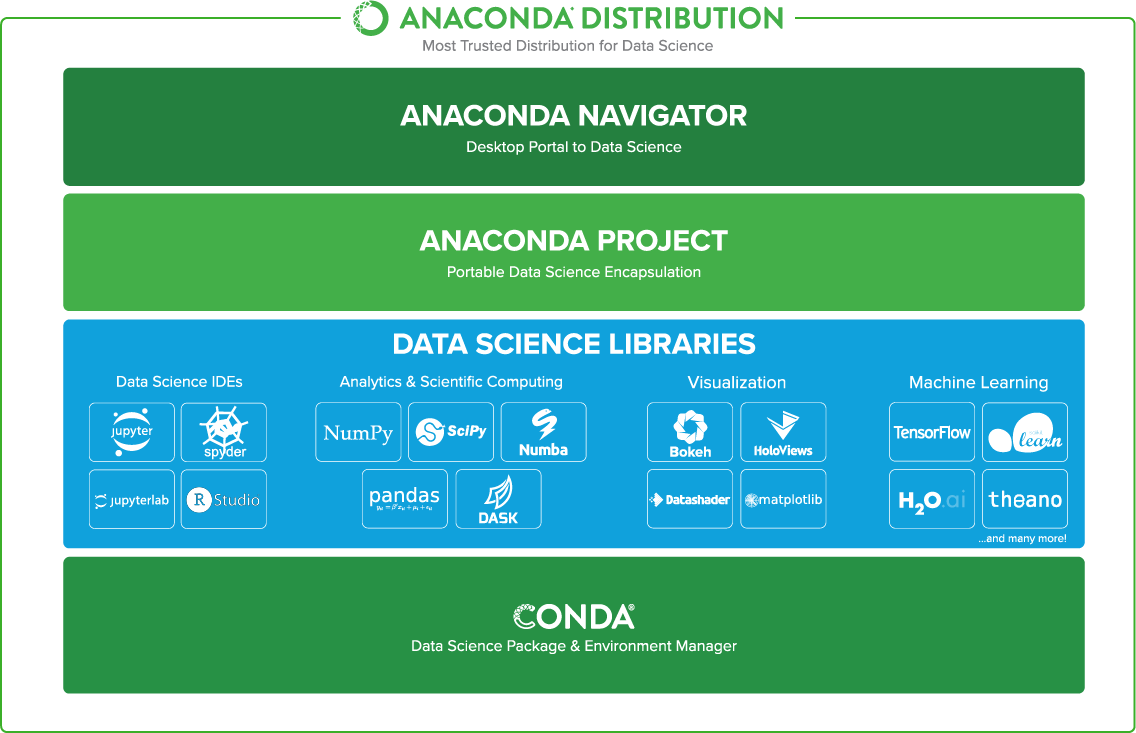
La estructura de la distribución de Anaconda. Podemos observar que librerías vienen pre instaladas.
Introducción al dominio del problema
Usaremos el set de datos de IRIS el cual es conocido como el “Hello World” de Machine Learning. Este set incluye información del ancho y longitud de pétalos y sépalos de flores IRIS. En base a esa información se tiene definido a qué tipo de especie pertenece.
Con estos datos, entonces ¿Qué problema queremos resolver?
Proponemos el siguiente: queremos predecir a qué tipo de especie pertenece una flor de iris conociendo las dimensiones de sus pétalos y sépalos.
Para iniciar importamos la librería Pandas, la cual permite importar el set de datos que tenemos en un archivo .csv y trabajarlo como un data frame. Un data frame permite almacenar la información como una tabla en la que se tiene un conjunto de filas y columnas. Lo potente de esto es que podemos realizar operaciones con ellas, como agregar/eliminar columnas y operar sobre ellas.
Luego ejecutamos la función head() para pre visualizar los primeros 5 registros.
import pandas as pd
df_iris = pd.read_csv("iris.csv")
df_iris.head()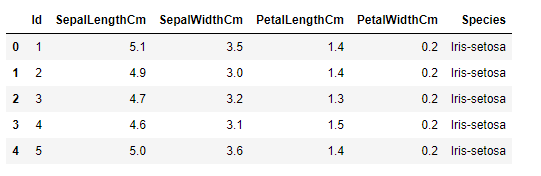
La columna id para nuestro problema no es relevante debido a que el data frame maneja un id interno para identificar cada registro, por lo que podemos dropear la columna con la funcion drop() para tener un set de datos más limpio.
df_iris.drop(['Id'], axis=1, inplace=True)
df_iris.head()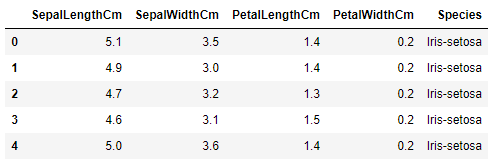
Análisis de la información
Ya tenemos nuestro set de datos importado, ahora vamos a realizar un análisis exploratorio para detectar patrones que nos ayuden a entender el problema que estamos tratando.
Empecemos detectando los tipos de especies posibles. La función unique() me permite identificar los diferentes valores para una columna del data frame.
df_iris['Species'].unique() 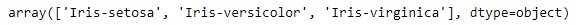
Con esto podemos ver que solo tenemos 3 especies de flores de IRIS. Uno de estos valores va a ser la salida de nuestro modelo.
Ahora analicemos la cantidad de información que tenemos para cada tipo de especie.
pd.value_counts(df_iris['Species']).plot.bar( figsize = (8,3))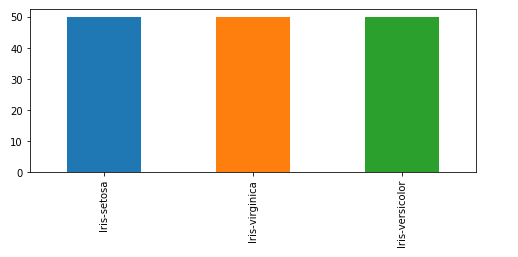
Con esta información se observa que el set de datos se encuentra “balanceado”, es decir, que para cada especie tenemos 50 registros diferentes, lo que es lo ideal para el entrenamiento. Podría darse el caso de que nuestro set tenga puros datos de una especie específica lo cual es peligroso ya que el modelo no sabría cómo interpretar otras especies diferentes.
Analicemos con un gráfico tipo ScatterPlot si podemos encontrar alguna relación entre las dimensiones de los sépalos por tipo de especie
df_setosa = df_iris[df_iris.Species=="Iris-setosa"]
df versicolor = df_iris[df_iris.Species=="Iris-versicolor"]
df_virginica = df_iris[df_iris.Species=="Iris-virginica"]
ax = df_setosa.plot.scatter(x='SepalLengthCm',y='SepalWidthCm',color = 'Green',label ='Setosa')
ax2 = df_versicolor.plot.scatter(x='SepalLengthCm',y='SepalWidthCm',color = 'Red',label ='Versicolor', ax=ax);
df_virginica.plot.scatter(x='SepalLengthCm',y='SepalWidthCm',color = 'Blue',label ='Virginica', ax=ax2, figsize=(10,5));
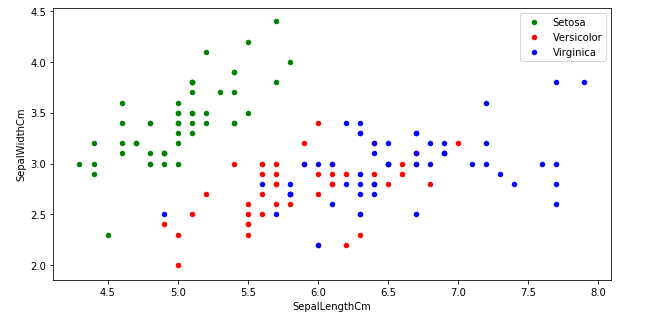
En este gráfico podemos observar que hay un patrón definido. Los sépalos de la especie Setosa tienen una longitud menor al resto y un ancho ligeramente mayor, lo que provoca que se encuentren separados del resto de los puntos. Para las 2 especies restantes no tenemos una forma clara de diferenciarlas en grupo
Analicemos ahora las dimensiones de los pétalos.
df_setosa = df_iris[df_iris.Species=="Iris-setosa"]
df_versicolor = df_iris[df_iris.Species=="Iris-versicolor"]
df_virginica = df_iris[df_iris.Species=="Iris-virginica"]
ax = df_setosa.plot.scatter(x='PetalLengthCm',y='PetalWidthCm',color = 'Green',label ='Setosa')
ax2 = df_versicolor.plot.scatter(x='PetalLengthCm',y='PetalWidthCm',color = 'Red',label ='Versicolor', ax=ax);
df_virginica.plot.scatter(x='PetalLengthCm',y='PetalWidthCm',color = 'Blue',label ='Virginica', ax=ax2, figsize=(10,5));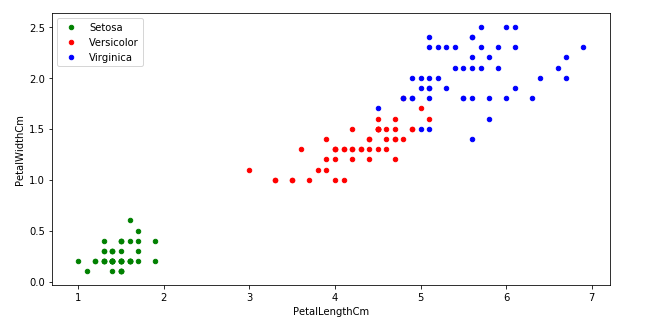
En este gráfico podemos observar que las 3 especies presentan una importante diferencia entre ellas al analizar esta cualidad. Esto quiere decir que los pétalos importan para definir el tipo de especie a la que pertenece una flor.
Podemos usar esta información para la construcción del modelo.
Construcción del modelo
Para entender el proceso que vamos a realizar tenemos el siguiente diagrama:
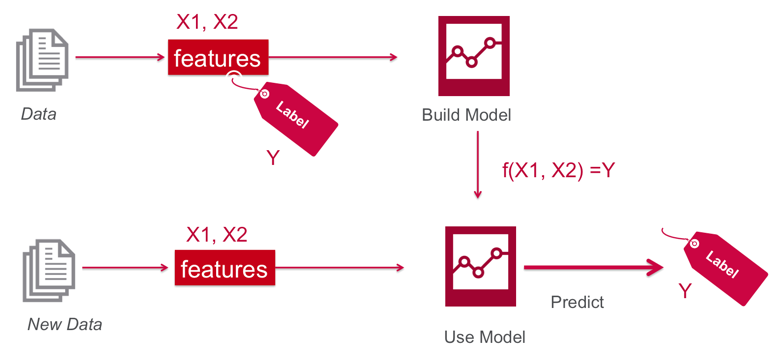
En esta imagen está reflejado todo lo que vamos a hacer:
- Con el set de datos vamos a identificar los Features y los Labels de nuestro problema
- Con esa información vamos a entrenar un modelo.
- Teniendo información nueva vamos a usar nuestro modelo para realizar las predicciones
Seguramente se estarán preguntando ¿Qué es un Feature? y ¿Qué es un Label?
Un Feature es una propiedad del problema la cual queremos usar para predecir resultados. El análisis de datos nos ayuda a descubrir cuales son los features más importantes. Justamente por esta razón, es porque se dedica tanto tiempo en el mismo. Un ejemplo son las dimensiones de pétalos y sépalos.
Los Labels son los resultados que esperamos del problema. En nuestro caso son los diferentes tipos de especies de IRIS
Un dato no menor es la elección del algoritmo que vamos a usar. Existen diferentes tipos y algunos se ajustan mejor a un tipo de problema específico, pero en general la elección se realiza por prueba y error de acuerdo al resultado obtenido.
En nuestro caso elegiremos el algoritmo KNN. Para ello usaremos la librería Scikit-Learn la cual es muy conocida para Machine Learning por su facilidad de uso y la inclusión de diferentes algoritmos.
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_scoreTenemos importado nuestro algoritmo, pero ¿como vamos a probar su eficacia?
Lo que hacemos es segmentar el set de datos de entrenamiento y usarlo para validar la eficacia del modelo. Existen diferentes técnicas como Holdout, Cross-Validation, Resubstitution, etc..
Usaremos la técnica Holdout la cual divide el set de entrenamiento en 2 partes. Una de ellas se va a utilizar para el entrenamiento del modelo y la restante la usaremos para validar y calcular la precisión. Lo haremos en un ratio de 80%-20%
set_entrenamiento, set_validacion = train_test_split(df_iris, test_size = 0.2, random_state=4)Con esto tenemos armado set de datos para entrenar y para validar. Nos queda el trabajo de elegir nuestros features, para ello usaremos el análisis hecho previamente.
Algo que observamos es que las dimensiones de sépalos se encontraban agrupadas en 2 conjuntos de acuerdo al ScatterPlot. Usemoslos como features.
Lo que vamos a realizar ahora es dividir el set de entrenamiento en 2 data frames. Uno de ellos tendrá solo los features (las variables del problema) y el otro solamente los labels (los resultados)
#Construccion data frame de entrenamiento
set_entrenamiento_caso_sepalos_x = set_entrenamiento[['SepalLengthCm','SepalWidthCm']]
set_entrenamiento_caso_sepalos_y=set_entrenamiento.Species
#Construccion data frame de validacion
#Este data frame lo usaremos para predecir
set_validacion_caso_sepalos_x= set_entrenamiento[['SepalLengthCm','SepalWidthCm',]]
#Este date frame lo usaremos para validar los resultados para el calculo de precision
set_validacion_caso_sepalos_y =set_entrenamiento.Species
print("Set de entrenamiento con features")
display(set_entrenamiento_caso_sepalos_x.head())
print("Set de entrenamiento con labels")
display(set_entrenamiento_caso_sepalos_y.head())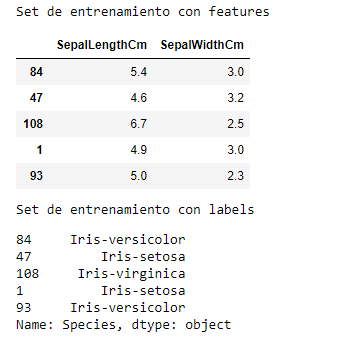
Podemos ver en la imagen los 2 data frame.
Ahora vamos a construir el modelo y agregamos el set de datos de features y de labels al mismo. Con esto el algoritmo realiza el entrenamiento y será capaz de predecir resultados
modelo = KNeighborsClassifier(n_neighbors=3)
modelo = modelo.fit(set_entrenamiento_caso_sepalos_x,set_entrenamiento_caso_sepalos_y)Listo ¡Ya tenemos el modelo armado y entrenado! ¿Sencillo no? Ahora hagamos las predicciones. Para ello el modelo tiene una función llamada predict la cual recibe como parámetro los features que queremos predecir y como salida tendremos un array con los labels a los cuales el algoritmo predijo.
Este array lo agregaremos como nueva columna al set de validación que usamos para predecir y con ello tendremos los resultados para cada flor
prediction=modelo.predict(set_validacion_caso_sepalos_x)
df_resultado_final = set_validacion_caso_sepalos_x.copy()
df_resultado_final['tipo_especie'] = prediction
df_resultado_final.head()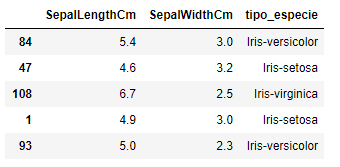
Ahora podemos calcular la eficacia de nuestro modelo validandolo con los resultados que conocemos. Para ello Scikit-Learn tiene un paquete de metrics el cual nos devuelve el porcentaje de eficiencia en base a los resultados predecidos y los que conocemos
print('La eficacia del algoritmo fue',
metrics.accuracy_score(prediction,set_validacion_caso_sepalos_y)) 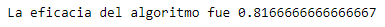
¡Tenemos un resultado de 81% de eficacia! ¡Pero ahora viene lo bueno! Si usamos lo aprendido del análisis de datos sabemos las dimensiones de los pétalos permiten distinguir las especies fácilmente, a diferencia de los sépalos.
Usando los pétalos como features veamos qué diferencia tenemos
#Similar al caso anterior. Me armo los set de entrenamiento y validación con petalos como features
set_entrenamiento_caso_petalos_x = set_entrenamiento[['PetalLengthCm','PetalWidthCm']]
set_entrenamiento_caso_petalos_y=set_entrenamiento.Species
set_validacion_caso_petalos_x= set_entrenamiento[['PetalLengthCm','PetalWidthCm',]]
set_validacion_caso_petalos_y =set_entrenamiento.Species
#Armamos de nuevo el modelo
modelo_petalos=KNeighborsClassifier(n_neighbors=3)
modelo_petalos.fit(set_entrenamiento_caso_petalos_x,set_entrenamiento_caso_petalos_y)
prediciones_modelo_petalos=modelo_petalos.predict(set_validacion_caso_petalos_x)
Ahora calculemos la eficacia de nuestro nuevo modelo
print('La eficacia del algoritmo fue',accuracy_score(prediciones_modelo_petalos,set_validacion_caso_petalos_y))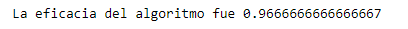
¡Un 96%! Mucho mejor que el modelo anterior. La mejora de este resultado tuvo que ver con el análisis previo efectuado. En el pudimos observar que habían features que eran más significativos que el resto lo que hizo que el algoritmo aumente la precisión. Con esto podemos ver nuevamente la importancia de detectar patrones en la información y la elección de los features.
Conclusiones Finales
Este ejemplo representó cada uno de los pasos necesarios para resolver un problema aplicando algoritmos de Machine Learning.
Me gustaría nuevamente remarcar la importancia del análisis de los datos. Con una simple exploración detectamos patrones conocidos que pudimos aplicar en la implementación y lo mejor es que nuestros resultados mejoraron logrando casi un 97%. Esto es lo que nos va consumir la mayor cantidad de tiempo: entender los datos
Lo siguiente que vamos a hacer en el próximo post es exportar este modelo entrenado en Python en un archivo, levantarlo en una aplicación en Java y exponer la consulta de predicciones como por medio de un servicio REST.
¡Muchas Gracias!