¿Alguna vez te preguntaste cómo hace Netflix para recomendarte películas que van acorde a tus géneros favoritos? ¿Cómo hace Amazon para recomendarte productos similares en base a tus búsquedas? ¿Cómo Google califica los correos como SPAM? ¿Cómo SIRI, CORTANA o ALEXA detecta los comandos de voz? O si te gusta la Fórmula 1 como a mi ¿Cómo hacen para predecir la ventana de vueltas para el cambio de neumáticos?
Las respuestas a estas preguntas tienen un común denominador. Machine Learning
En este post vamos a introducirnos en el mundo de Machine Learning. Así que ¡Todos abordo!
¿Qué es Machine Learning?
Se conoce a Machine learning como la rama de computación en la se que aplican algoritmos de inteligencia artificial para resolver un problema a partir de datos.
El algoritmo es capaz de aprender con un set de datos de entrenamiento sin la necesidad de estar explícitamente programados y de dicho aprendizaje se genera un modelo del cual podremos realizar predicciones a nuestros problemas.

¿Aprenden sin necesidad de programarlos? ¿Estamos más cerca de SkyNet y el fin del mundo? Estos algoritmos aprenden en base a un set de datos y los resultado son predicciones.
Contestando a la primera pregunta que nos hicimos, Netflix aprende nuestros “gustos” a medida que vemos más películas, refinando sus predicciones. Si miramos solamente películas de cierto género nos recomendará películas del mismo por ejemplo.
Como Machine learning utiliza datos para el entrenamiento de los algoritmos, la rama está muy de la mano con la disciplina Data Science
¿Qué es Data Science?
Data Science es una disciplina que se encarga de analizar, procesar y extraer información de datos para la resolución de un problema.
El análisis de datos es un pilar muy importante en Machine Learning debido a que el rendimiento de los algoritmos dependen del set de datos que usemos. Tanto es así que estaremos la mayor parte del tiempo analizando los datos, transformándolos y eligiendo el algoritmo más acorde que codeando la implementación del mismo.
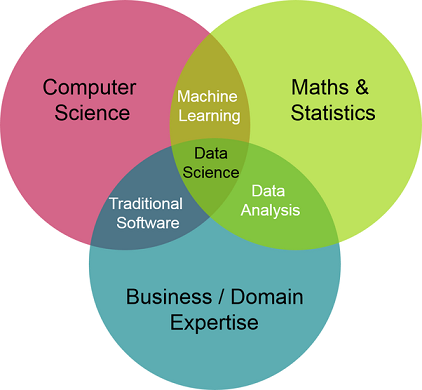
Los pilares de Data Science
Como podemos ver en la imagen de arriba, los pilares de Data Science son fundamentales. Necesitamos tener una base de conocimientos en matemática y estadística para analizar y visualizar la información. También necesitamos una base en el conocimiento del dominio que estamos trabajando para entender los problemas del negocio. Finalmente necesitamos tener conocimientos en el dominio de la ciencia computacional, en criollo, necesitamos tener la habilidad de desarrollar el código para la implementación de diferentes algoritmos.
Tipos de Algoritmos
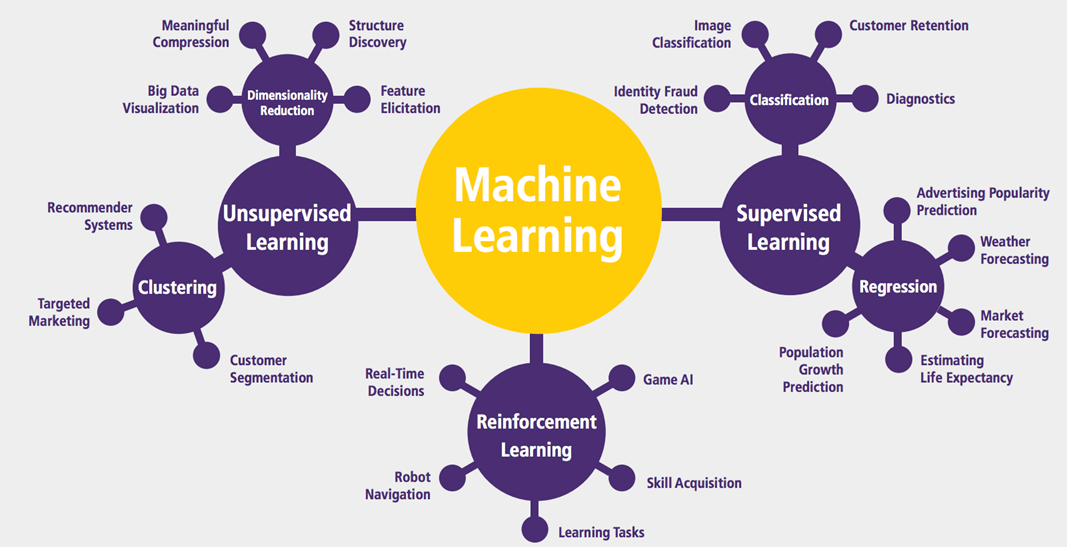
Tipos de aprendizajes en Machine Learning
En la foto de arriba podemos ver las diferentes ramas de aprendizaje que tenemos en Machine Learning. Vamos a realizar una breve descripción de los tipos de algoritmos a aplicar. La principal diferencia radica en el tipo de aprendizaje de cada uno
Aprendizaje Supervisado
En este tipo, como bien dice su nombre, el aprendizaje es supervisado. ¿Que quiere decir esto? Sabemos qué tipo de resultados deseamos obtener y se encuentran relacionados con los datos que vamos a usar.
El principal objetivo es construir un modelo que sea capaz de realizar predicciones con datos nuevos o no conocidos a partir de un set de datos cuyos resultados ya conocemos.
Por ejemplo: La clasificación de si un correo es SPAM es un problema de aprendizaje supervisado. En este caso, sabemos qué resultados esperamos (Es SPAM o NO ) y para el entrenamiento del algoritmos tenemos información histórica de mails, en las que tenemos identificado cuáles son SPAM o NO

Hay que entrenar a la IA con los resultados
Los problemas más comunes para resolver con este tipo de aprendizaje son 2:
- Clasificación: Como bien dice su nombre, la idea es generar un modelo que sepa predecir a qué clase pertenecen los nuevos datos. Ejemplo: Predecir si un correo es SPAM
- Regresión: En este caso la idea es generar un modelo que sepa aproximar la nueva información a una variable numérica continua. Por ejemplo: Predecir el valor de un producto a futuro en el mercado, predecir el porcentaje precipitación de lluvias
Los algoritmos de aprendizaje supervisado más conocidos son:
- Linear Regression
- Logistical Regression
- Random Forest
- Gradient Boosted Trees
- Support Vector Machines (SVM);
- Neural Networks
- Decision Trees
- Naive Bayes
- K-Nearest Neighbor
Aprendizaje No Supervisado
En este tipo, a diferencia del anterior, los resultados no los conocemos y quedan por definir. El set de datos tiene información sin ninguna relación con los resultados. El principal objetivo es explorar la estructura de la información para extraer información relevante, detectar patrones recurrentes y categorizar.
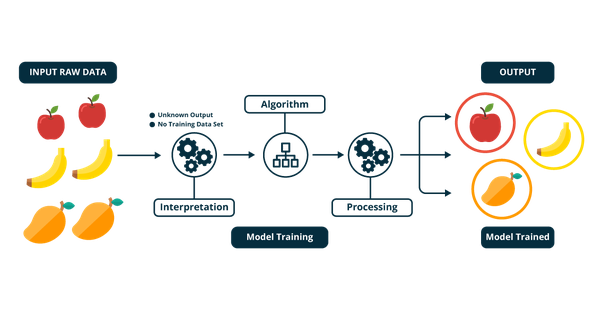
El algoritmo interpretó el set de datos y como salida categorizó la entrada
Para este tipo de aprendizaje se realizan las siguientes técnicas:
- Clustering: La idea es poder segmentar el set de datos en diferentes grupos basado en patrones detectados sin necesidad de tener conocimiento previo.
- Reducción de Dimensionalidad: Se utiliza en el caso que queramos reducir las dimensiones de nuestro set de datos. En general, a medida que aumentamos la información del set de datos también consumimos más recursos por lo que puede llegar al caso en el que esto sea imposible de procesar. Una solución es reducir las dimensiones de los datos generando un set más compacto y rápido de procesar pero sin perder la relevancia de la información
Los algoritmos más comunes de aprendizaje no supervisado son:
- K-means Clustering
- t-SNE
- PCA
- SVD
Aprendizaje por Refuerzo
Este tipo de aprendizaje consiste en entrenar al algoritmo para generar un modelo de tal forma que sea capaz de intentar producir como salida el mejor resultado o el más performante en cierto contexto a partir de un sistema de recompensas.
El modelo se entrena de tal forma que cada acción que realice recibe recompensas o penalizaciones. A partir de prueba y error encuentra el resultado que maximiza las recompensas.
Debido a esto recibe el nombre de aprendizaje por refuerzo.

Alpha Zero es un IA entrenada para jugar al ajedrez con este tipo de aprendizaje. Tiene aproximadamente un ELO superior a 3400. Magnus Carlsen, actual campeón mundial, tiene un ELO de 2882. ¿Te animas a jugarle?
Una aplicación de este tipo de algoritmos es en el control de tráfico inteligente, que intenta encontrar la forma más óptima de organizar el tránsito de una ciudad o como bien dice la imagen, en el entrenamiento para jugar juegos.
¿Cómo continuamos?
Esta fue una pequeña introducción al mundo de Machine Learning y Data Science. Obviamente quedan muchos conceptos fuera de la misma, pero con esta información estamos encaminados para avanzar por cuenta propia
En los próximos posts veremos cómo construir un modelo utilizando un algoritmo y lo emplearemos para predecir resultado en base a nuevos datos.
¡Gracias!