Cuántas veces nos ha sucedido estar jugando un juego y guardar a cada rato la partida, pero sin sobreescribir la anterior por si las dudas? Y si te dijera que esta práctica se replica en ámbitos profesionales ? No lo creerías verdad?
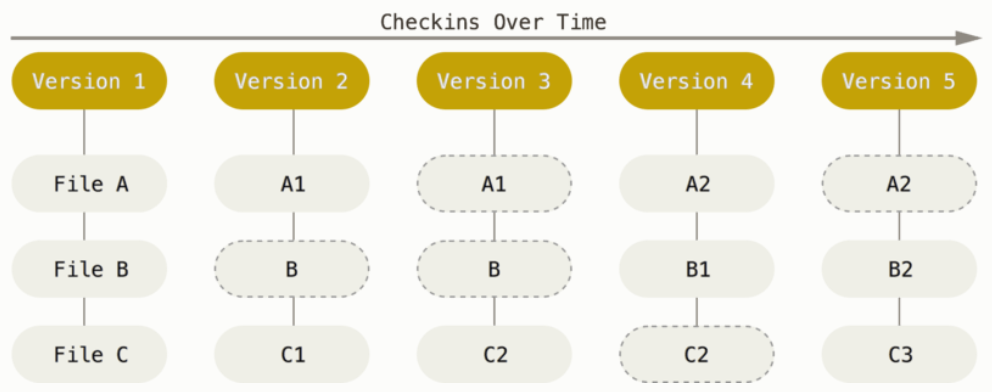
Efectivamente, hace tiempo en el ámbito del desarrollo de software y durante el proceso de desarrollo de las aplicaciones, sucedía que, a medida que se iban desarrollando nuevas versiones de un producto o agregando funcionalidades o incluso enmendado errores, se creaban nuevas carpetas que resultaban ser réplicas de la anterior versión sumado a su nuevas líneas de código, lo cual, conlleva tener al menos una carpeta en nuestra computadora, con distintas subcarpetas que alojan distintas versiones de un proyecto, lo cual en términos no solo de ocupar lugar en memoria resulta ser un problema.
Otro problema con el que nos encontraríamos en dicho escenario es al momento de desarrollar en equipo, ya que deberíamos andar transfiriendo dicha carpeta que aloja el proyecto vía los medios adecuados, pero ojo, no te vayas a equivocar de carpeta, es decir de versión…
Y esto es un pequeño pantallazo sobre las problemáticas que conllevaba manejar las versiones de estas maneras.
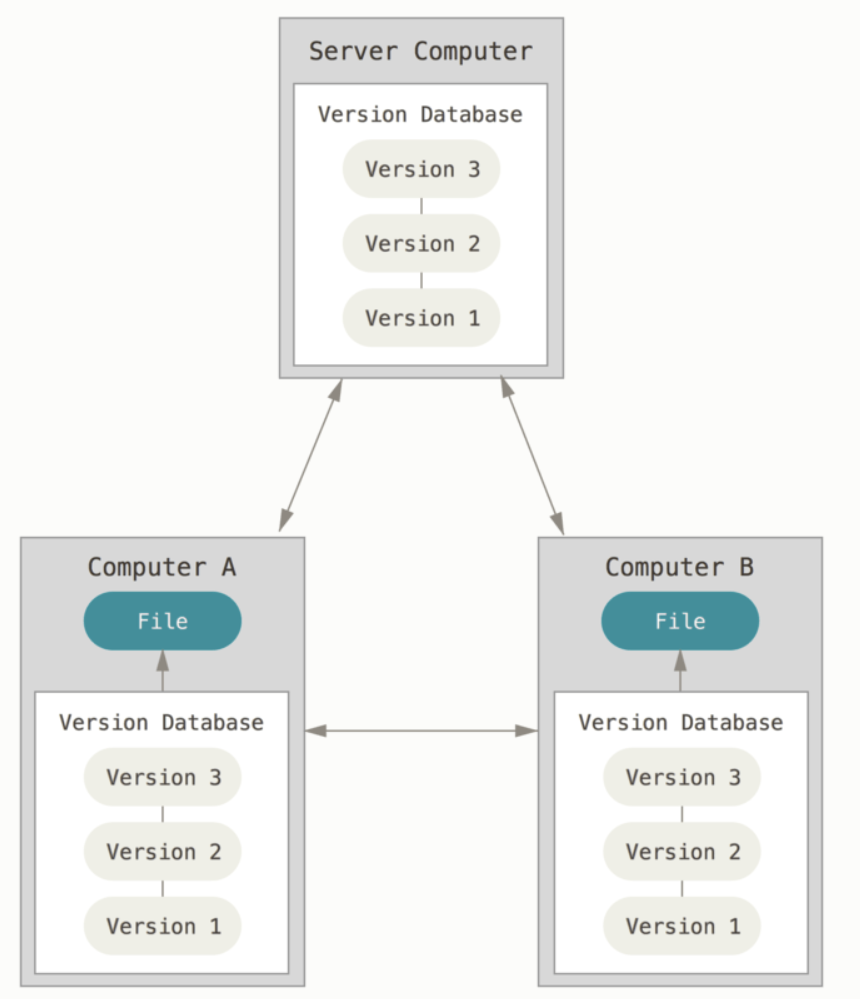
Ante todas estas adversidades es que llega Git, Git es un Sistema de Control de Versiones Distribuido. Bueno pero ¿qué es? Es un sistema que registra los cambios realizados en un archivo o conjunto de archivos a lo largo del tiempo, de modo que puedas recuperar versiones específicas en cualquier momento.
Puntualmente la palabra Distribuido quiere decir que los sistemas no solo obtienen la última copia instantánea de los archivos, si no que se replica completamente en el repositorio local del sistema, de esta manera, si un servidor deja de funcionar y estos sistemas estaban colaborando a través de él, cualquiera de los repositorios disponibles en los sistemas puede ser copiado al servidor con el fin de restaurarlo.
Comencemos a trabajar con Git
1. Comandos para obtener y crear proyectos
Lo primero es ubicarse en el directorio donde vamos alojar el proyecto y por ende tener un control de sus versiones, una vez allí, abrimos la terminal, puede ser la de nuestro sistema operativo, la de nuestro editor de código o la propia de Git, Git Bash, una vez allí ejecutaremos el comando “git init”.
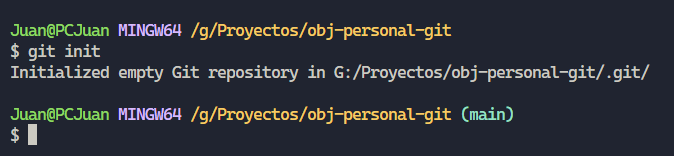
Al ejecutar dicho comando, no notaremos nada fuera de lo normal, sin embargo en dicho directorio se acaba de crear un subdirectorio “.git”, el cual contiene todos los archivos necesarios para el repositorio, de momento podemos ignorarlo.
De esta manera ya podemos crear nuestro proyecto, comenzar a darle seguimiento, “modificar” nuestras versiones y posteriormente “confirmarlas” en nuestra rama local “main”, incluso enviar nuestros cambios a un repositorio remoto, pero todo a su tiempo, ya llegaremos a eso.
En el caso que deseemos obtener una copia de un repositorio remoto existente, por ejemplo, un proyecto asignado en el cual nuestro trabajo es desarrollar nuevas funcionalidades, el comando adecuado es “git clone” seguido de la URL del repositorio remoto, por ejemplo “git clone https://github.com/JuansARG/portfolio-frontend-v2”
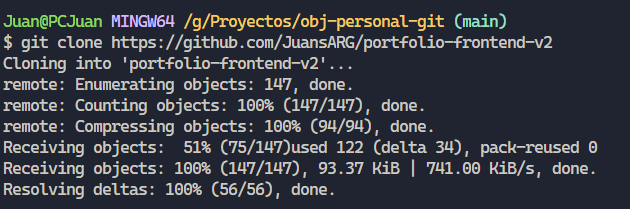
Una vez ejecutado el comando, nos creará una carpeta llamada “portfolio-frontend-v2”, en su interior aloja el subdirectorio necesario .git, además de todos los archivos de la última versión del repositorio en cuestión. Cabe destacar que al inicializar nuestro repositorio local mediante “git clone”, no es necesario utilizar el comando ”git init”.
En el caso que deseemos personalizar el nombre de la carpeta que aloje nuestro proyecto podemos indicarlo en el mismo comando, dejando un espacio luego de la url del repositorio en cuestión seguidamente del nombre, por ejemplo: “git clone https://github.com/JuansARG/portfolio-frontend-v2 mi-portfolio”
Para esta altura ya podremos comenzar a trabajar con nuestro sistema de control de versiones distribuidos en la rama local “main”, seguramente te preguntarás qué es una rama ? De a poco iremos abarcando cada uno de estos temas.
2. Ciclo de vida y comandos básicos.
Antes de comenzar a ver los comandos básicos creo necesario definir los distintos estados en los que podemos encontrar nuestros archivos.
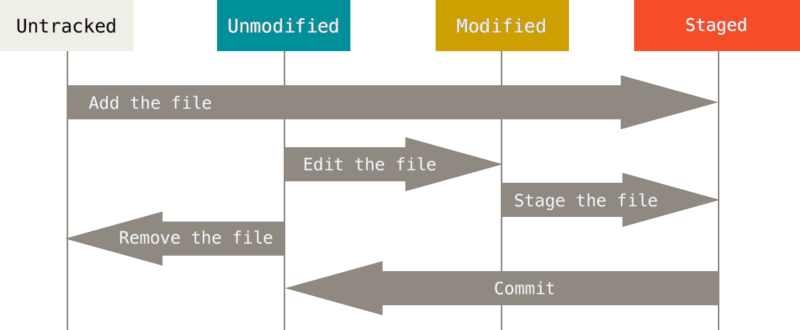
Entiéndase estado como la situación en la que se encuentran nuestros archivos respecto al control de versiones. En el caso de nosotros haber iniciado nuestro control de versiones utilizando “git init” sobre un directorio que ya tiene archivos de nuestro proyecto o posteriormente haber creado el proyecto, todos estos archivos van a encontrarse “untracked”, es decir, sin rastrear/sin seguimiento. Para darle seguimiento a estos archivos, deberemos “agregarlos” en nuestra área de preparación “staging area” con el comando “git add .”, y posteriormente confirmarlo con el comando “git commit -m ‘mi primer commit!’" para crear una instantánea de nuestro proyecto. Cuando hablo de instantánea, me refiero a como se encuentra el proyecto en X punto del tiempo, cabe destacar que cada una de estas instantáneas tiene un identificador único que se denomina “hash”. De a poco iremos viendo cada uno de los comandos antes mencionados, primero quiero dejar claro cómo funciona el ciclo de vida.
Una vez que nosotros creamos una instantánea de nuestro proyecto, todos estos archivos que fueron agregado al área de preparación y confirmados, pasan a tener el estado “unmodified” que como lo indica el nombre, se encuentran sin modificar y como se imaginaran, que pasa si modificamos uno de estos archivos que tiene dicho estado? Exactamente, este archivo pasará al estado “modified”, es decir modificado. Ahora, si nosotros deseamos crear una instantánea de cómo se encuentra nuestro proyecto luego de haber modificado algunos de los archivos, debemos primero, agregarlos a nuestro área de preparación y luego confirmar. Al confirmarlo se creará una instantánea con un hash único al que podremos acceder mediante “git checkout “[hash del commit]”. Este va a ser el ciclo que se va a repetir una y otra vez a lo largo del desarrollo de nuestro proyecto.
Retomando los ejemplos anteriormente exhibidos, continuemos avanzando con el escenario en el que utilizamos “git init”. Rápidamente voy a crear un proyecto con Astro, una vez creado vamos a utilizar un nuevo comando para ver en qué situación se encuentran nuestros archivos, utilizando el comando “git status”.
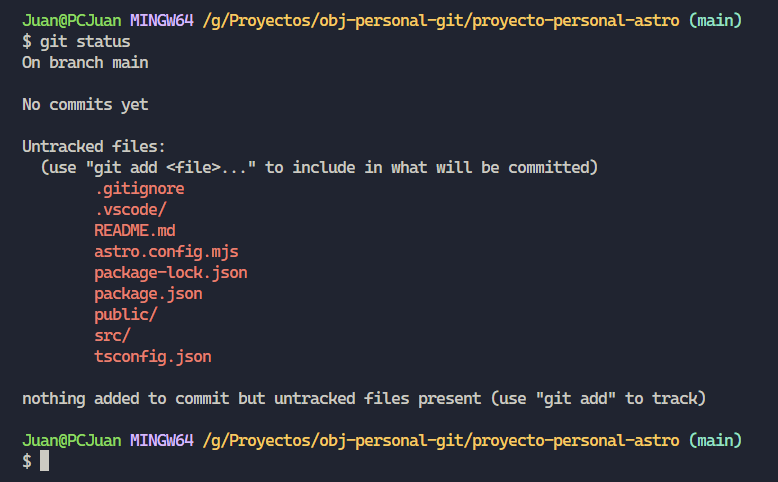
Como podrán observar en la imagen, git nos indica que todos los archivos en color rojo están “untracked”, cabe aclarar que no es este caso, pero los archivos “modified” git también los marca en rojo. Este comando nos será de mucha utilidad para identificar en qué etapa del ciclo de vida se encuentran nuestros archivos.
De momento vamos a agregar todos nuestros archivos al “staging area”, utilizando el comando “git add .”, en el caso de querer agregar únicamente un solo archivo, basta con “git add [ruta del archivo]”.
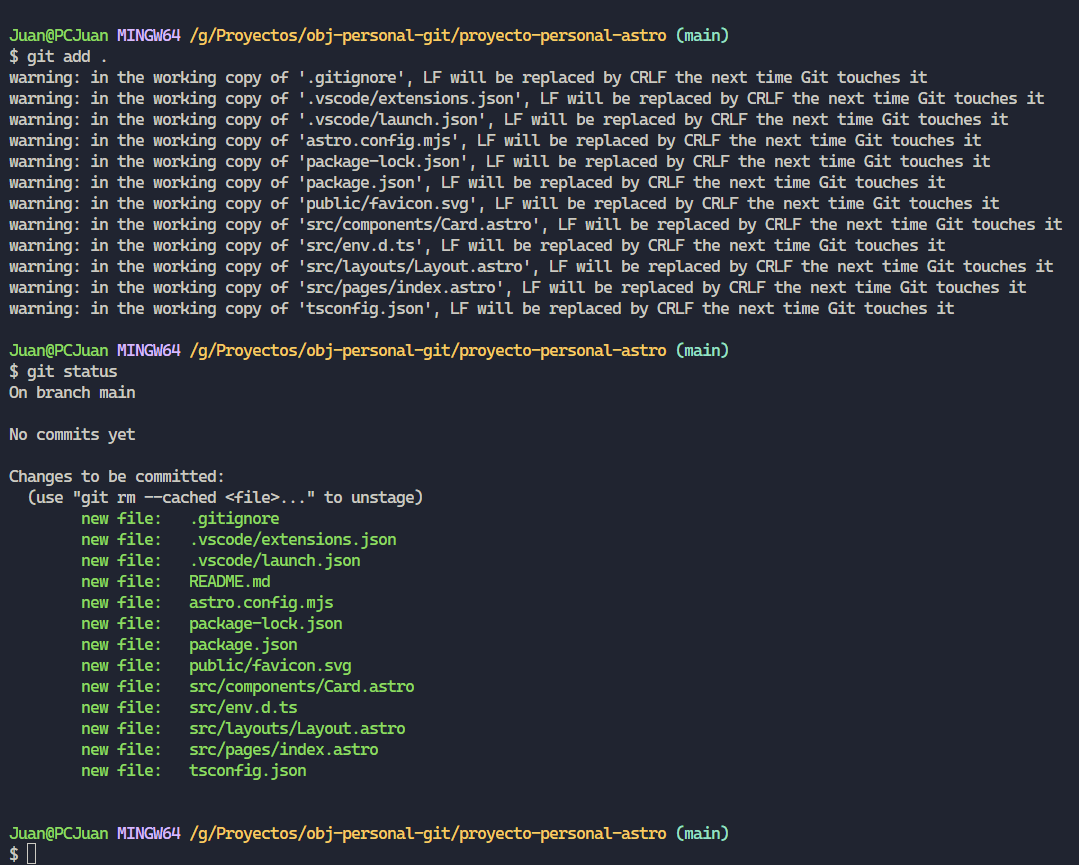
Ahora al ver nuevamente el status podemos observar que git está detectando los cambios indicando que se tratan de nuevos archivos, y que dichos archivos están listos para ser confirmados, es decir para crear una instantánea.
Ahora estamos listos para crear una instantánea de cómo se encuentra nuestro proyecto, a la cual podremos acceder cuando lo consideremos necesario a través de su hash. Para realizar dicho paso utilizaremos el comando “git commit -m [mensaje de confirmación]“.
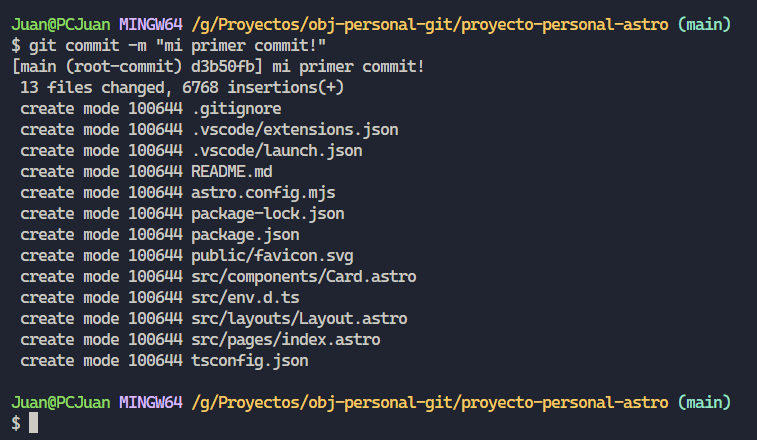
Si ahora ejecutamos un “git status” podemos observar que no hay nada para confirmar.

Con esto es suficiente para poder continuar trabajando en nuestro proyecto, digamos que ya tenemos un punto de restauración al cual volver en caso de ser necesario.
Sin embargo vamos a contemplar otras casuística para ser más abarcativo. Repasemos qué sucedió cuando hicimos nuestro primer git status.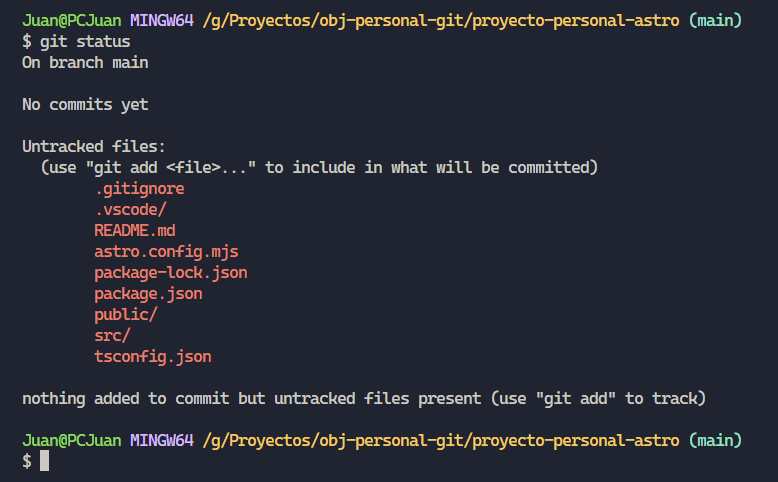
En ese momento git nos indicaba, que todos los archivos en rojo, se encontraban “untracked”. Ahora qué sucede si luego de haber creado nuestra primera instantánea, es decir haber realizado nuestra primera confirmación, modificamos un archivo, lo guardamos y comprobamos nuevamente el status?
Para este ejemplo voy a modificar el archivo README.md y voy a agregar texto en la primera línea del mismo.

Evidentemente no es lo mismo que nos mostró en aquel primer git status. Esto se debe a que el archivo está siendo “trackeado” y ha detectado un cambio, cambio que no se encuentra en el “staging area” para su posterior confirmación. Ahora, Git nos muestra distintos caminos a seguir, uno de ellos es el antes mencionado, “git add” para poder agregar dicha modificación al área de preparación y el otro camino consta de utilizar “git restore [nombre del archivo]” para poder descartar los cambios, en caso de querer descartar todos los cambios podemos utilizar “git restore .”. Como ya conoces el paso a paso del proceso de utilizar ”git add”, en este caso vamos a utilizar “git restore README.md” y ver que sucede.

A simple vista no sucede nada, pero si entramos al archivo los cambios han sido descartados, comprobemos el status una vez más.

Efectivamente nuestra área de trabajo se encuentra en orden para comenzar a trabajar.
Vamos con la yapa, en una de las imágenes nos recomendó un comando más precisamente “git commit -a -m [mensaje de confirmación]”, en resumen, es similar al que utilizamos para confirmar, sin embargo tiene un extra y se trata del “-a”, al agregar esto estamos agregando todas las modificaciones que se ha provocado en los archivos que se encuentran “trackeados”, ojo con esto, únicamente en los que se encuentran trackeados, es decir, si nosotros creamos un archivos, por ejemplo README2.md, y seguidamente hacemos “git commit -a -m [msj]”, ese archivo no se va a incorporar a la instantánea ya que no ha sido trackeado, para trackearlo debemos hacer el tradicional “git add README2.md”; en definitiva, dicho comando nos sirve para obviar el “git add” siempre y cuando deseemos crear una instantánea incluyendo los cambios en archivos ya existente en la instantánea anterior, usarlo a conciencia!
Para finalizar con esta categoría, veamos un comando más, “git diff”, me resulta extremadamente interesante y nos sirve para ver las modificaciones que se llevaron a cabo, en el caso de haber modificado alguno. Para este ejemplo voy a modificar el archivo index.astro, voy a guardar el archivo y seguidamente voy a ver que nos muestra el nuevo comando.
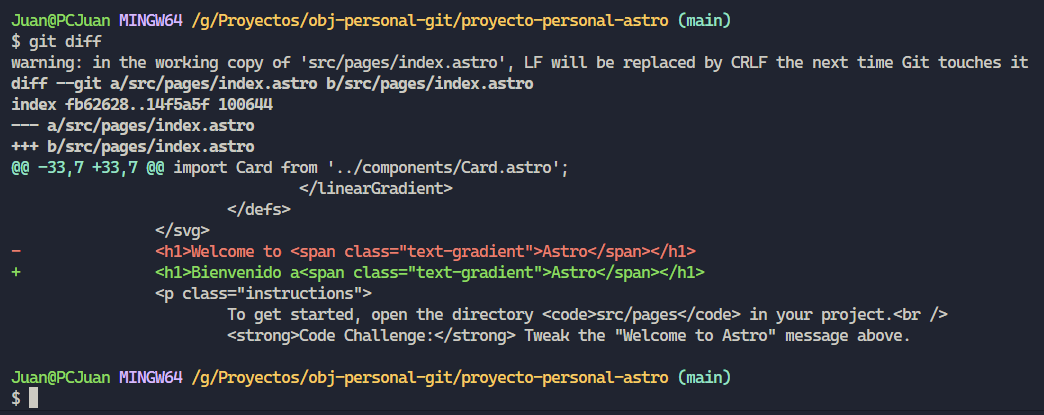
A pesar de mostrarnos bastante cosas, en resumen el código en color rojo, es el que fue modificado/remplazado por el código de color verde, como podrán ver la modificación que hice fue simplemente remplazar “Welcome to” por “Bienvenido a”.
Sin embargo hay que tener cuidado con este comando, ya que ”git diff”, así sin mas nos nuestra los cambios que aún no están en el área de preparación, es decir, si nosotros los agregar a dicha área, no nos devolverá nada.
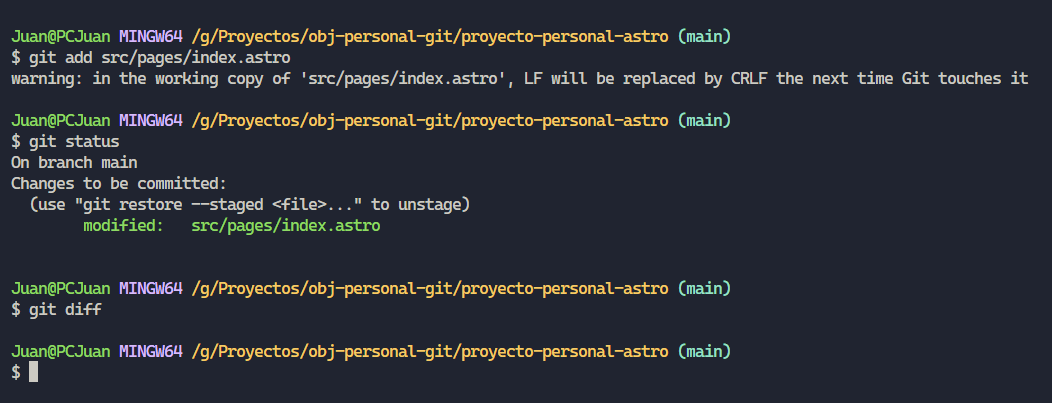
Sin embargo, entre nuestra última instantánea y nuestra actual área de preparación hay diferencias! Para poder ver estas diferencias, debemos utilizar “git diff –staged”, quien en definitiva va comparar directamente contra nuestra última instantánea.
En resumen podemos utilizar “git diff” para ver los cambios que están sin preparar y “git diff –staged” para ver los cambios que ya preparamos y compararlos con nuestra última instantánea.
3. Manejo de ramas y fusiones
Vamos a entrar en un terreno un tanto más complejo y lo primero que me gustaría comentar es que para trabajar con un sistema de control de versiones debemos saber dónde estamos parados, por ende me gustaría dejar claro el concepto de HEAD. HEAD no es más que un puntero, quien valga la redundancia apunta hacia el lugar donde nos encontramos.
Por otra parte creo indispensable introducir el concepto de ramas, digamos que son los caminos va tomando nuestro proyecto, veámoslo con un ejemplo mejor…
Nuestros ejemplos se estaban llevando a cabo en la rama main verdad? Es decir nuestro proyecto tiene un solo camino denominado main que curiosamente es a donde está apuntando nuestro puntero HEAD, cabe destacar que el HEAD puede apuntar también a distintas instantáneas, en otras palabras nuestro proyecto tiene un solo camino actualmente.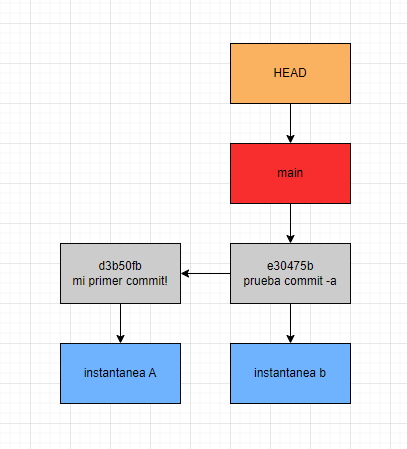
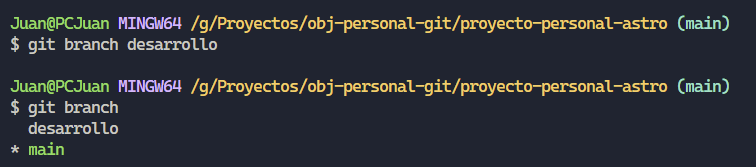
Antes de crear una rama, vamos a utilizar el comando “git branch” para poder visualizar las ramas que posee actualmente nuestro proyecto.
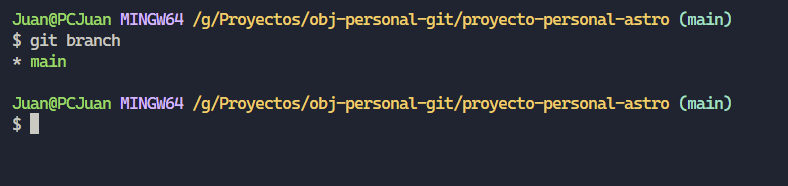
Como podrán observar solo tenemos una, por ende nuestro gráfico anterior, representa correctamente la situación en la que nos encontramos, continuemos creando una rama nueva y observar qué sucede, para dicha acción utilizaremos el comando “git branch [nombre de la rama]”, vamos a llamarla “desarrollo”. Cabe destacar que dicho comando no nos mostrará nada en la terminal, solamente creará la rama, en cuanto al posicionador HEAD no cambiará hacia dónde apunta.
Una vez creada vamos a ver nuevamente las ramas que posee nuestro proyecto, y como podrán observar tenemos una nueva.
¿Cómo afecta este cambio al gráfico anterior?
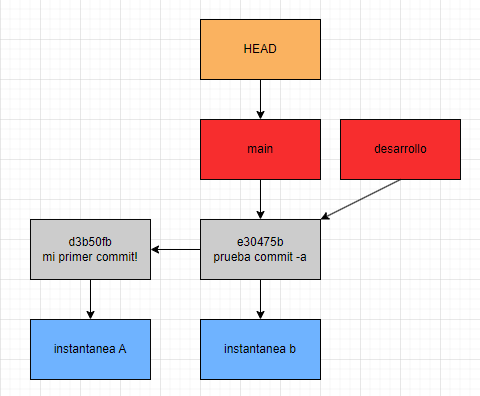
Teniendo en cuenta los conceptos antes mencionados, si quisiéramos comenzar a trabajar desde la rama desarrollo lo único que deberíamos hacer es cambiar hacia donde apunta HEAD, para esto podemos utilizar el comando “git checkout [nombre de la rama a la que queremos apuntar]”, ademas de hacer eso, vamos a modificar algún archivo agregarlo al área de preparación y tomar una instantánea. Seguidamente adjunto como queda el flujo luego de todos estos cambios.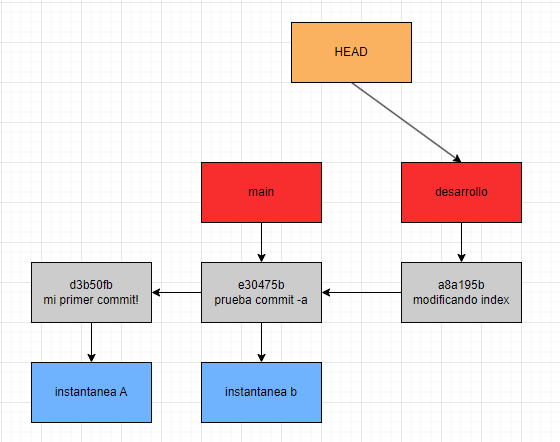
Cabe destacar que “git checkout [nombre de la rama]” no solo cambia nuestro apuntador HEAD, si no que también revierte los cambios de nuestro directorio de trabajo –siempre y cuando no hayan sido agregados a nuestra área de preparación– dejándolos tal y como estaban en la última instantánea, es decir nuestra última confirmación.
También me gustaría agregar el comando “git branch -d [nombre de la rama]”, comando muy útil que nos sirve para borrar la rama de nuestro repositorio local y el comando “git checkout -b [nombre de la nueva rama]”, que nos será útil para crear y cambiar nuestro apuntador HEAD hacia esa nueva rama, es como un atajo de git branch + git checkout.
Actualmente, se agregó el comando “git switch”, quien también sirve para cambiar nuestro apuntador HEAD de manera más puntual, a diferencia de “git checkout” no tiene tanta flexibilidad y por ende es menos propenso a errores.
Ahora nos adentraremos en el concepto de fusión de ramas, para entender esto tenemos que tener en cuenta que Git nos permite fusionar ramas. Imaginemos el siguiente escenario, estábamos trabajando en nuestra rama de desarrollo implementando una nueva funcionalidad, y nos informan que surgió un error en producción, inmediatamente dejamos lo que estamos haciendo previa preparación y confirmación para no perder lo avanzado en nuestra rama .
El paso a seguir para poder largar un hotfix que resuelve el problema en producción, va a ser crear una nueva rama a partir de nuestra rama main, para esto, vamos a posicionar el apuntar HEAD en main utilizando “git switch main” –recuerden que estamos en desarrollo–, y seguidamente vamos a crear una nueva rama y a posicionar el apuntar HEAD en ella, rama donde vamos a desarrollar el hotfix, para esto utilizaremos el comando “git checkout -b hotfix_1”, una vez allí ya podremos desarrollar la solución y posteriormente crear la instantánea. En este caso desarrolle la solución y cree la instantánea utilizando el comando “git commit -a -m “resuelto error en index”. Veamos cómo quedó el gráfico.
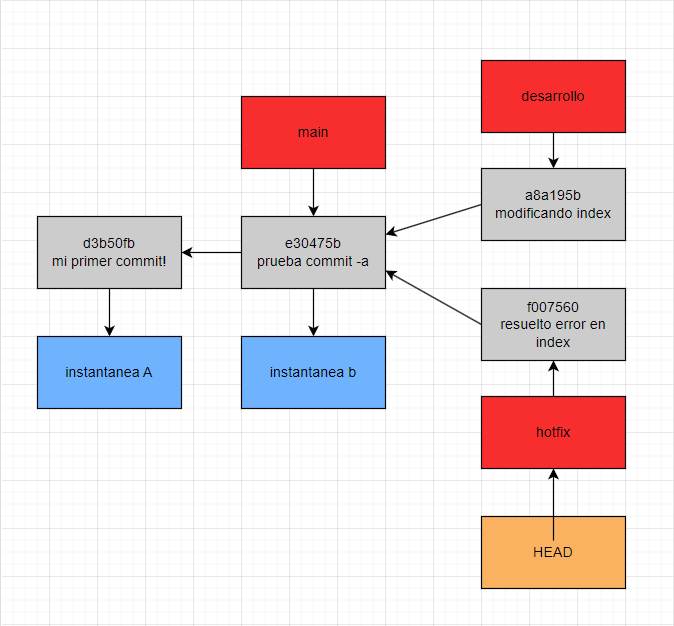
Avanzamos bastante, de hecho resolvimos el problema que había en producción pero ¿cómo fusionamos nuestra rama hotfix dentro de main ?
Para esto utilizaremos un nuevo comando, “git merge [nombre de la rama que queremos fusionar]”, muy mucho importante, debemos estar parado en la rama que quieres utilizar de base, para este ejemplo primero ubicar el apuntador HEAD hacia la rama main, utilizando “git switch main”, una vez allí procederemos a ejecutar el comando “git merge hotfix”, veamos que nos devuelve.

Esta fusión para Git es bastante sencilla ya que no hay divergencia, es decir sin ir más lejos la rama hotfix_1 no es más que una instantánea basada en la instantánea a la que apunta main –es decir la anterior confirmación–, es este motivo por el cual lo que hace git únicamente es avanzar –de ahí el Fast-forward– el apuntador main al commit que apunta hotfix_1, este sería el resultado.
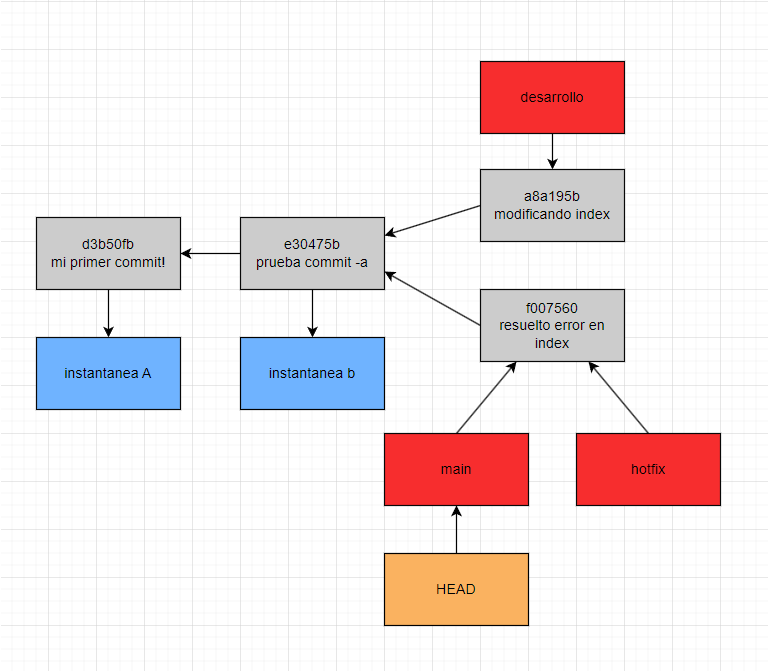
Sin embargo el comportamiento de Git es otro cuando hay divergencia, es decir ramificación, supongamos que nosotros estamos trabajando en una nueva funcionalidad en nuestra rama de desarrollo, una vez finalizada creamos nuestra instantánea, y posteriormente deseamos fusionar la rama de desarrollo con la rama main.
Para hacer la fusión, vamos a ubicar el apuntador HEAD en la rama main, y vamos a ejecutar “git merge desarrollo”, lo que va a hacer Git por detrás es una fusión a 3 bandas, va a fusionar el extremo de las 2 ramas y el ancestro común de ambas, en lugar de simplemente avanzar el apuntador como en el anterior ejemplo. Una vez hecha la fusión, nos va a crear una nueva instantánea, la cual como curiosidad tiene más de un padre, por lo general las instantáneas tiene un solo padre exceptuando este caso. Veamos cómo quedó nuestro flujo.
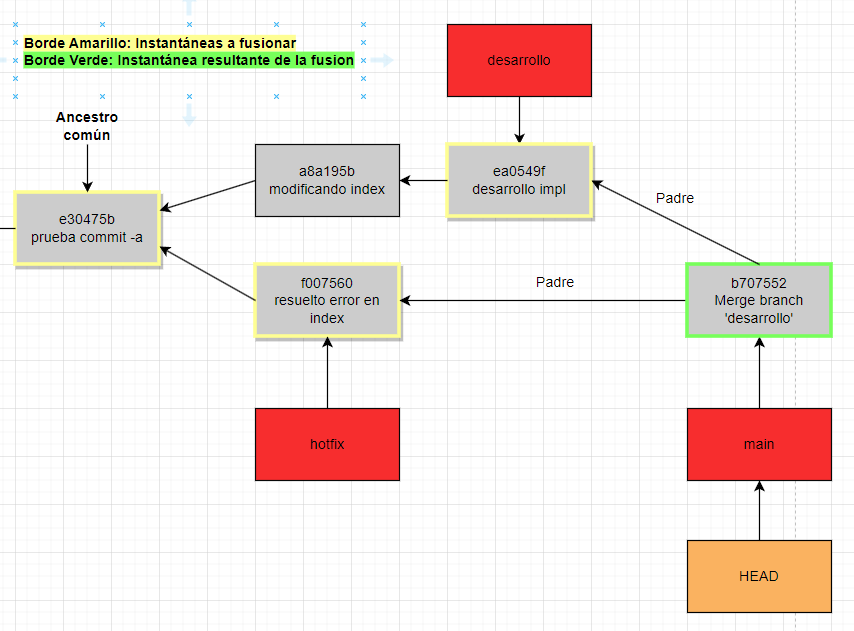
En este caso la instantánea se generó automáticamente porque no hubo conflictos. Entiéndase un conflicto como querer poner dos piezas de código en un mismo lugar dentro de un mismo archivo, Git no sabrá con cual quedarse y dicho conflicto se deberá resolver a mano, pero eso lo dejaremos para otro momento. De momento quiero dejar claro que, si no hay conflictos se creará automáticamente la instantánea resultante de la fusión, caso contrario, deberemos resolver los conflictos y luego confirmar.
Dando por finalizada esta sección, me gustaría agregar un poco de contenido extra que me resulta útil, dicho contenido abarca métodos para deshacer cambios entre otros, más precisamente los comandos “git commit –amend -m” y “git restore”.
Comencemos utilizando el orden de mención, “git commit –amend -m [mensaje de confirmación]” no será útil para situaciones en la que ya creamos una instantánea pero nos olvidamos de agregar una modificación o un archivo al área de preparación. Con dicho comando en resumen sobreescribimos la última instantánea. Mejor vamos con un ejemplo, recientemente creamos una instantánea sin embargo nos olvidamos de modificar el contenido de nuestro componente Footer.astro, entonces como no deseamos crear otra instantánea si no sobreescribir la anterior, lo que podemos hacer es modificar dicho archivo y guardar el archivo, sin necesidad de agregar al área de preparación dicha modificación, directamente utilizamos el comando en cuestión, quien sobreescribirá la instantánea anterior con este último cambio. También se sobreescribirá el mensaje de confirmación.
Continuemos con “git restore [directorio del archivo]” si bien ya lo vimos en el anterior apartado me gustaría ahondar un poco más; este comando nos va a servir para, como indica su nombre restaurar un archivo a su estado de confirmación anterior. Es decir, por ejemplo, modificamos el archivo Footer.astro, sin embargo por X razón, queremos restaurar el archivo, es deshacer los cambios y continuar trabajando en otro archivo. Este escenario es el ideal para utilizar “git restore /src/components/Footer.astro”.
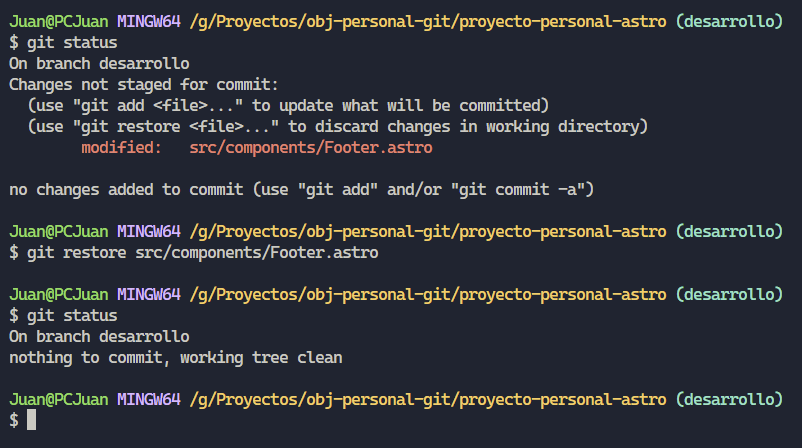
Por otra parte también podemos utilizar dicho comando para retirar un archivo o modificación del área de preparación. Para este caso utilizaremos “git restore –staged [directorio del archivo]”.
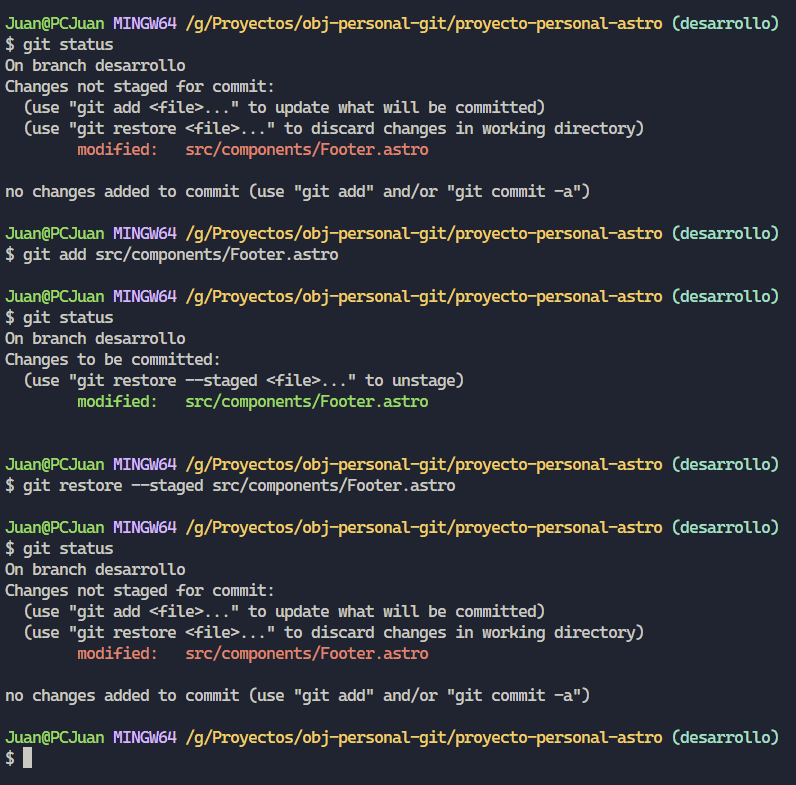
Como podrán observar se encontraba en el área de preparación y luego de ejecutar el comando y comprobar su estado, nos indica que ha sido modificado y que no se encuentra en el área de preparación.
4. Para compartir y actualizar proyectos
Para entender esto de compartir y actualizar proyectos, debemos tener en claro que no solo existen los repositorios locales, también existen los repositorios remoto los cuales son alojados en webs como Github, Gitlab, Bitbucket, entre otros; la diferencia sustancial es que la única manera de mover sus apuntadores es mediante comunicación vía red. Por otra parte, las ramas remotas funcionan como marcadores para recordarnos en qué estado se encontraban nuestros repositorios remotos la última vez que nos conectamos con ellos.
La nomenclatura para referenciarse a las ramas remotas es [nombre del repo/nombre de la rama], tengan en cuenta que por defecto Git denominara “origin” a nuestra rama remota. Mucho texto, que tal si guardamos nuestra rama main de nuestro proyecto en un repositorio de Github ? Ya habiendo creado nuestro repositorio en Github con el nombre “obj-personal-git” lo que voy a hacer es utilizar un nuevo comando "git push -u origin main", pero vamos a desglosar dicho comando, “git push” sirve para, digámosle empujar nuestra rama local al repositorio remoto, con la opción “-u” le estamos indicando que se establezca una relación de seguimiento es decir, de ahora en adelante cada vez que hagamos un “push” o un “pull” desde esta rama local hacia nuestro repositorio “origin” no deberemos indicar a qué rama estamos apuntando porque ya se encuentran relacionadas. Continuemos, la palabra “origin”, estamos indicando que le vamos a pegar al repositorio previamente configurado llamado “origin”, por último “main”, quiere decir que nuestra rama en el repositorio remoto se va a llamar “main” o en el caso que existe apuntamos a la rama main.
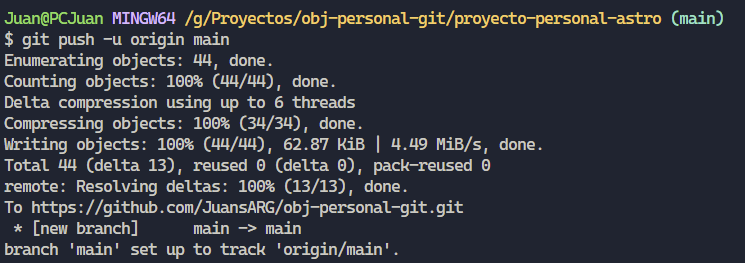
Sin embargo nos estamos saltando un paso, como se habrán dado cuenta, en el párrafo anterior mencione que nuestro repositorio se llama “origin” y que nosotros lo habíamos configurado, así que vamos a introducir un nuevo comando, "git remote add", dicho comando nos sirve para agregar un repositorio remoto, si, para agregar, nuestro proyecto puede apuntar a distintos repositorios remotos. Continuemos, con este comando agregaremos un repositorio remoto con el cual podremos comunicarnos, en mi caso el comando completo que ejecute para configurar mi proyecto fue: “git remote add origin https://github.com/JuansARG/obj-personal-git.git”, ahora ya sabemos para que sirve, sin embargo tiene dos agregados, el primero es la palabra “origin” sin ir más lejos es el nombre que le asignamos al repositorio y mediante el cual nos vamos a dirigir a él, podría ser “origin” como también “repojuancito”, el segundo y último agregado es la URL, que corresponde a la URL de mi repositorio en Github.
![]()
Es importante recordar que esta configuración se debe realizar antes de comunicarnos con el repositorio remoto, sea con el comando que sea.
Por lo general cuando creamos un repositorio en Github, el mismo nos indica cómo configurar y cómo hacer nuestro primer empuje a dicho repositorio, ¡es muy útil!.
Ahora, supongamos que estamos trabajando en nuestro proyecto con otro desarrollador. El antes mencionado “pushea” a la rama “desarrollo” un cambio, justo ese día yo estaba de día festivo. Asique al día siguiente tomo conocimiento de los avances y antes de comenzar a desarrollar, compruebo el estado de nuestro repositorio local con “git status”.
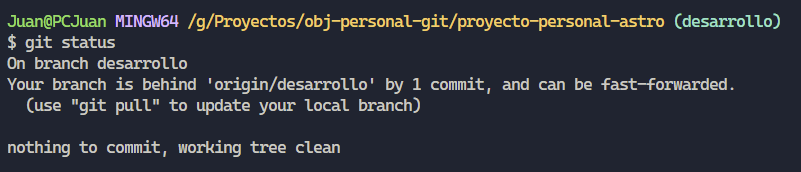
Como podrán observar nos indica que nos encontramos una instantánea detrás de la rama desarrollo de nuestro repositorio denominado “origin”, y nos recomienda usar “git pull” para actualizar nuestra rama local.
Ahora, ¿para qué sirve “git pull”? A simple vista como indica su nombre tira u obtiene algo, ese algo son las modificaciones que se llevaron a cabo en el repositorio remoto. Sin embargo para llevar a cabo dicha acción tienen que suceder dos cosas, obtener la información de esos cambios y fusionarlos o en otras palabras “git fetch” y “git merge”. Pasando en limpio lo que hace “git pull”, es descargar la información del repositorio remoto y de forma inmediata combinarlos en la rama que nos encontramos. Lo cual a simple vista no parece una mala idea sin embargo no puede traer algunos inconvenientes.
Dicho esto, recomiendo utilizar “git fetch” para descargar la información del repositorio remoto, tengan en cuenta que no va a modificar nuestra rama actual, por lo cual consecuentemente necesitaremos utilizar “git merge” para comenzar a fusionar las ramas, lo cual nos permite un mejor control sobre la fusión. En caso de que los cambios no sean significativos, definitivamente recomiendo utilizar “git pull”.
Les comparto el diagrama de cómo se vería visualmente todo lo antes mencionado utilizando “git pull” para obtener la información del repositorio remoto y actualizar la rama actual en la que nos encontramos. Tengan en cuenta que para este ejemplo se realizó una instantánea desde Github, por ende la rama desarrollo apunta a esa última instantánea.
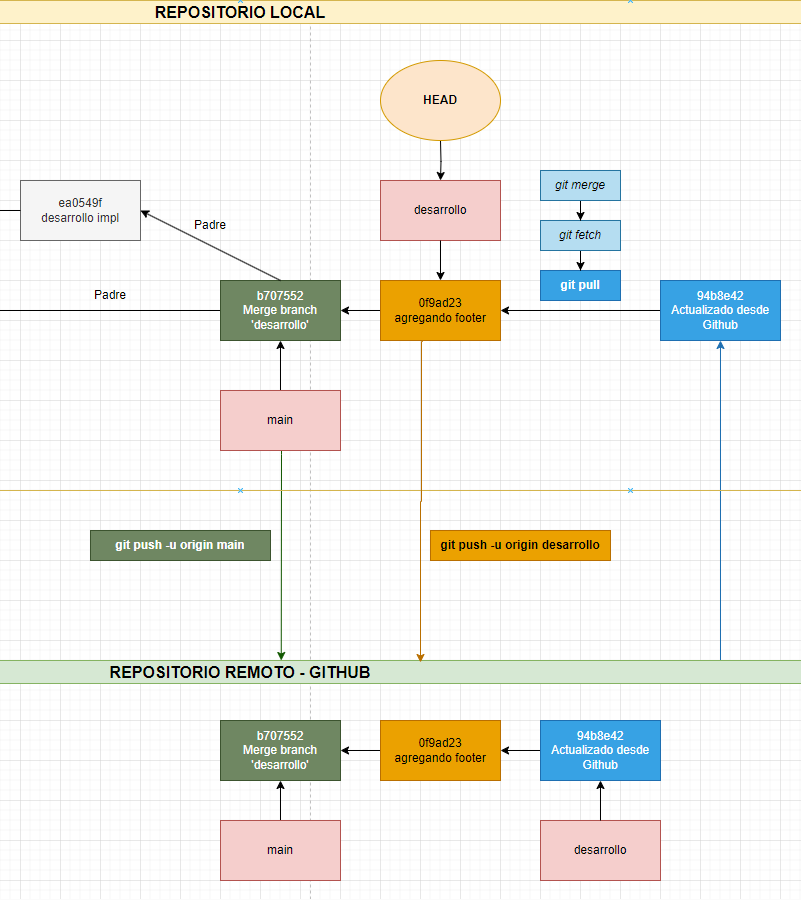
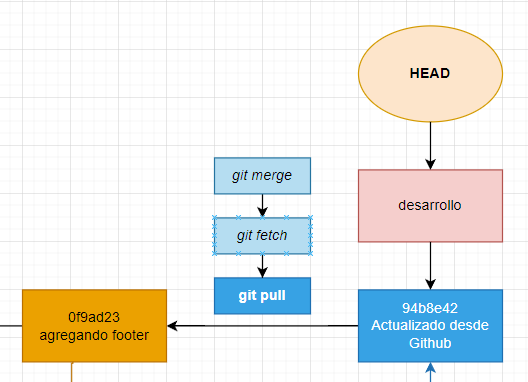
Tengan en cuenta que luego de hacer el “git pull” nuestra rama “desarrollo” va a apuntar a la última instantánea que acaba de obtener y fusionar con la actual rama en la que nos encontrábamos, quedando de la siguiente manera.
5. Configurando Git
A contracorriente de todo, por último vamos a configurar Git en nuestra área de trabajo, paso esencial para poder identificar quién realizó cambios en nuestro proyecto, entre otras cosas.
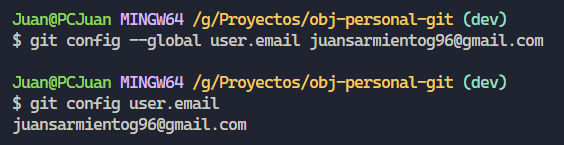
Para ver nuestra configuración actual debemos utilizar el siguiente comando “git config –list”, sin embargo los valores que creo más relevantes son los que corresponden a “user.email” y “user.name”. También podemos ver los valores de manera individual utilizando “git config [nombre de la propiedad]”. Por ejemplo:
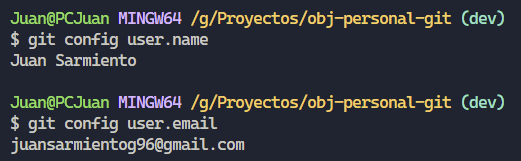
Para cambiar los valores que corresponden a esas propiedades simplemente debemos utilizar el comando “git config –global [nombre de la propiedad] [valor nuevo]”.
Un ejemplo cambiando el nombre:
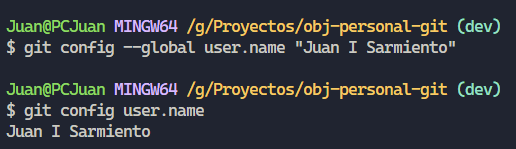
Otro ejemplo cambiando el email: