
En un mundo donde los datos fluyen a velocidades vertiginosas, enfrentar el procesamiento de grandes volúmenes de información puede ser un gran desafío. ¿Alguna vez tuviste que procesar numerosos registros, solo para encontrarte con un proceso lento, propenso a errores y con dificultades de recuperación en caso de fallo? La realidad es que, aunque los datos son vitales para nuestras operaciones, su manipulación no siempre es sencilla. Sin embargo, hay una solución que puede simplificar este proceso: Spring Batch.
Spring Batch es un framework ligero open source para procesamientos por lotes, como por ejemplo para hacer migraciones, cargas masivas que no necesitan interfaces de usuarios (tareas automáticas), etc proporcionándonos herramientas que nos permiten monitorizar estos procesos, disponer de logs, configuraciones, transaccionalidad, estadísticas, alertas, etc.
Spring Batch está construido sobre Spring Framework y tiene un diseño modular que nos permite utilizar solo los componentes que necesitamos.
Spring Batch proporciona soporte para:
- Leer y escribir datos de varias fuentes y formatos.
- Procesamiento de datos en lotes
- Gestión de transacciones
- Programación y ejecución de Jobs (bloques de trabajo).
- Manejo de errores y recuperación
Spring Batch se usa mucho en la comunidad de Java y tiene una base de usuarios grande y activa.
Ventajas:
- Ligero y fácil de usar: tiene una API simple e intuitiva que facilita el desarrollo de aplicaciones por lotes. Además, es liviano y no necesita muchos recursos para funcionar.
- Diseño modular: esto permite usar solo los componentes o herramientas que se necesitan, en definitiva, personalizarlo.
- Gestión de transacciones: proporciona soporte integrado para la gestión de transacciones, asegurando la coherencia y la integridad de los datos.
- Programación y ejecución de Jobs: ofrece un marco de programación y ejecución que permite ejecutar Jobs por lotes de forma programada o manual.
Desventajas:
- Escalabilidad limitada: Spring Batch está diseñado para el procesamiento por lotes en una sola máquina y es posible que no se escale bien para grandes conjuntos de datos.
- Soporte limitado para procesamiento distribuido: no proporciona soporte integrado para procesamiento distribuido, lo que puede ser una limitación para algunos casos de uso.
- Soporte limitado para lenguajes que no son Java: está basado en el lenguaje de programación Java lo que significa que puede no ser adecuado para proyectos que requieran soporte para otros lenguajes de programación.
Componentes: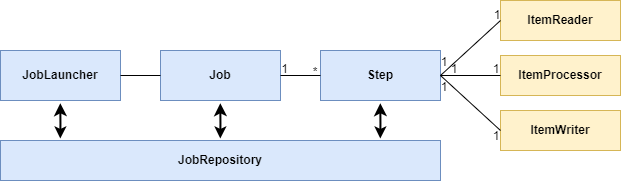
Los Jobs son los bloques de trabajo, los procesos que se ejecutan. Un job puede tener uno o varios Steps (pasos), que contienen cada uno un único ItemReader, ItemProcessor e ItemWriter. Un Job necesita ser ejecutado por un JobLauncher (el que usamos en los tests para probarlo, por ejemplo).
Los metadatos del proceso en ejecución necesitan guardarse en algún sitio, este lugar es el JobRepository.
En el "patrón de tres pasos" en Spring Batch, que involucra los componentes ItemReader, ItemProcessor e ItemWriter, es posible encontrarse con casos muy simples en los que no se requiere un procesamiento adicional. En tales situaciones, podría prescindirse del componente ItemProcessor.
Probablemente, la parte más interesante de todo este diseño resida en los steps. Spring Batch se basa en el enfoque “Chunk-Oriented”. Un "chunk" se refiere a un grupo o bloque de registros que se procesan y se escriben en una transacción. En forma más detalla:
- El reader lee un "chunk" de registros desde la fuente de datos, como una base de datos. Por ejemplo, podrías leer 100 registros de la base de datos en una sola operación.
- El processor procesa uno por uno los registros en el "chunk" según la lógica de negocio que hayas definido. Puedes realizar transformaciones, cálculos u otras operaciones en cada registro.
- El writer, luego de que cada chunk ha sido procesado, se escriben los resultados en el destino deseado, que podría ser otra base de datos, un archivo, o cualquier otro lugar.
Este ciclo de lectura, procesamiento y escritura se repite para cada "chunk" de datos. Una vez que se completa un "chunk", se pasa al siguiente hasta que todos los datos se hayan procesado.
Resumen:
La ventaja clave de Spring Batch es que puedes manejar grandes volúmenes de datos de manera más eficiente, ya que solo se cargan y procesan un número limitado de registros a la vez, en lugar de tratar de cargar todos los datos al mismo tiempo. Esto ayuda a evitar problemas de memoria y rendimiento en sistemas con limitaciones de recursos.
Además, si ocurre un error, no pierdes el trabajo realizado en todo el archivo dado que se está realizando el commit después de cada "chunk" de procesamiento, si algo sale mal, puedes deshacer solo ese "chunk" en lugar de revertir todo el procesamiento anterior. Esto minimiza el impacto de la falla y facilita la recuperación.