En un modelo orientado a objetos podemos utilizar uno de los pilares del paradigma POO para reutilizar comportamiento de nuestras clases, que es la Herencia. Pero cuando necesitamos persistir la información en un modelo relación, éste no contempla la herencia, ya que no tenemos comportamiento para reutilizar.
La diferencia entre ambos mundos hace preguntarnos, ¿Cómo persistimos información proveniente de una estructura jerárquica en Java?. En este posteo vamos a ver 3 estrategias que nos provee JPA para poder mapear éstas estructuras a un modelo relacional de bases de datos.
Las estrategias que podemos utilizar para la herencia son SINGLE_TABLE, JOINED y TABLE_PER_CLASS. Cada una tiene sus ventajas y desventajas dependiendo de nuestro diseño a nivel objetos, pero no debería condicionarnos al momento de insertar o consultar registros, ya que nuestro código cliente se abstrae de la estrategia empleada por el ORM, y sea cual sea la que implementamos, el programa debería seguir funcionando sin ningún cambio.
Para comparar y tomar una decisión sobre que estrategia utilizar, en este posteo vamos a estar analizando según 4 criterios:
- Distribución de atributos (disjuntos vs compartidos)
- Nullabilidad de campos
- Consultas polimórficas
- Integridad referencial
Estos criterios nos pueden facilitar la toma de decisiones, sabiendo que vamos a obtener algunos beneficios, pero seguramente también seamos conscientes de las limitaciones o dificultades que surjan de la decisión tomada. Es por eso que ninguna estrategia es mejor que otra, ninguna es mas eficiente que otra, por si mismas; sino que todo depende del contexto del programa y el uso que le vamos a dar.
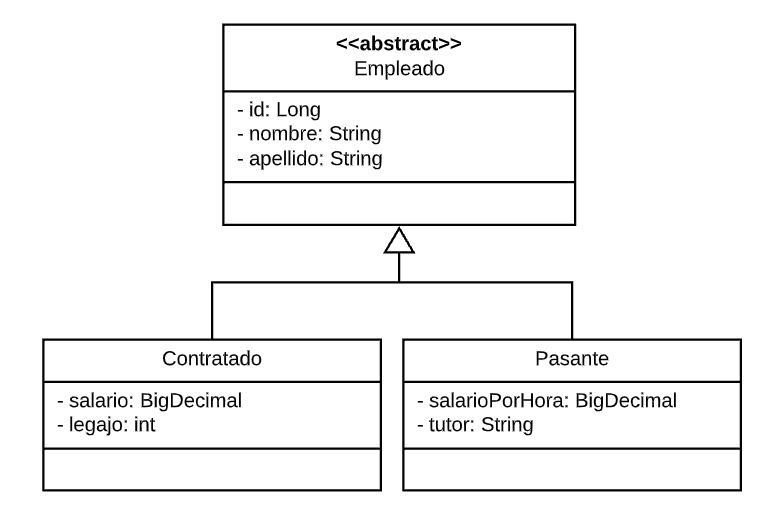
Para ver cada caso, nos vamos a basar en una simple jerarquía de herencia, con una clase abstracta y dos subclases, donde tenemos dos tipos de empleados, uno Contratado con sus atributos, y uno Pasante con otros atributos.
SINGLE_TABLE
Mapea toda la jerarquia a una sola tabla, con todos los atributos existentes en la superclase y en las subclases. Definimos la estrategia, con la annotation @Inheritance en la superclase
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public abstract class Empleado {
@Id
@GeneratedValue
private Long id;
private String nombre;
private String apellido;
}
@Entity
public class Pasante extends Empleado {
private BigDecimal salarioPorHora;
private String tutor;
}
@Entity
public class Contratado extends Empleado {
private BigDecimal salario;
private int legajo;
}
Si consultamos la base de datos, tenemos una sola tabla con el nombre de la superclase, con todos los atributos de todas las clases, y además una columna extra, que representa el campo discriminador para poder identificar a que subclase pertenece el registro.

Al ver como queda la tabla, podemos notar que dependiendo de la cantidad de atributos, esta estrategia podría generar confusiones en el modelo relacional, ya que nos quedaría una tabla demasiado grande, con campos que representan clases distintas en el modelo de objetos. Además, no tenemos la posibilidad de tener campos nulleables en las clases hijas, ya que por ejemplo si ponemos que 'salario' nunca sea nulo, vamos a tener un problema al querer insertar un registro de tipo Pasante, que no cuenta con ese atributo a nivel objetos.
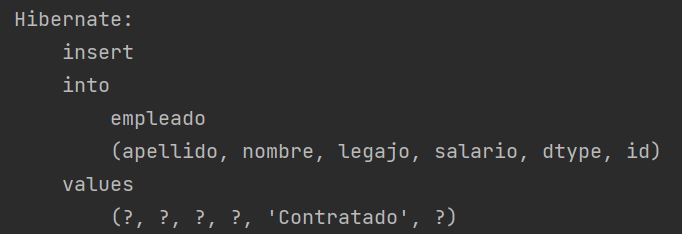
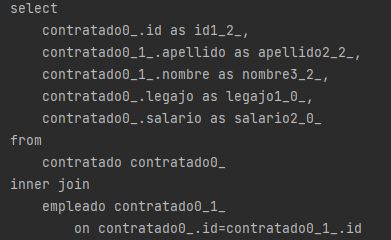
La inserción de registros se hace de manera directa sobre la tabla 'empleado', insertando solo los campos correspondientes al tipo de clase que se quiere insertar. Por ejemplo, si queremos insertar un empleado Contratado
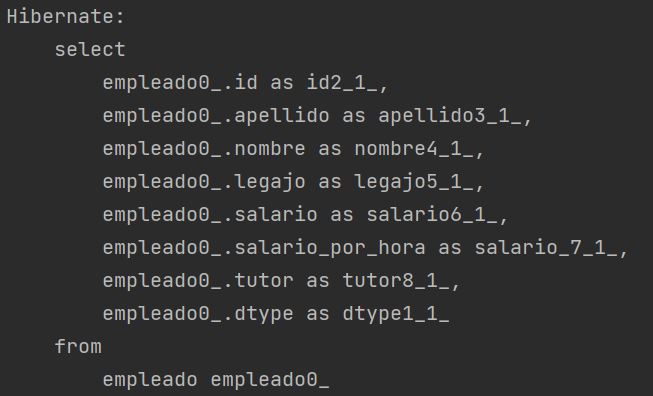
Para las consultas, podemos notar una pequeña diferencia entre consultas polimórficas (obtener objetos de tipo Empleado) o no polimórficas (obtener objetos de una subclase especifica).
Si la consulta es polimórfica, tenemos la ventaja que se hace directamente sobre la tabla, por ende la velocidad de respuesta puede ser mas rápida que otras estrategias.
Cuando la consulta no es polimórfica, tenemos la misma ventaja que la polimórfica, pero la diferencia es que en el WHERE se filtra por el tipo de la clase que se desea obtener.
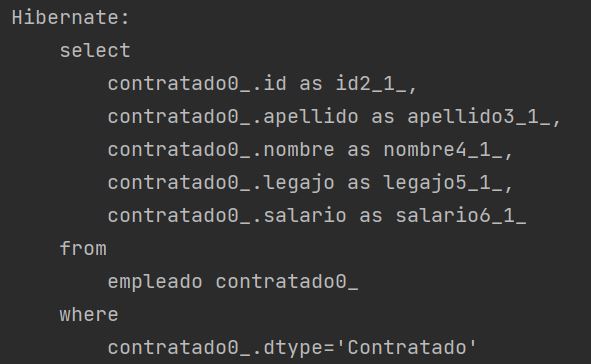
JOINED
Ésta estrategia genera una tabla por cada clase de la jerarquía, sea abstracta o concreta. Es decir que cada atributo de las clases van a estar en su tabla correspondiente de la base de datos, y mediante JOINS entre las subclases y la superclases se pueden obtener los objetos.
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
public abstract class Empleado {
@Id
@GeneratedValue
private Long id;
private String nombre;
private String apellido;
}
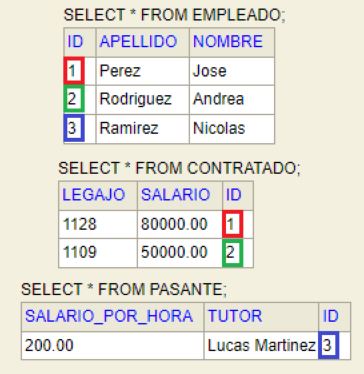
En la base de datos, podemos ver las 3 tablas 'empleado', 'contratado' y 'pasante'. De ésta manera vemos que las tablas son mas fácil de entender a diferencia de SINGLE_TABLE, ya que el esquema queda mejor normalizado y no vamos a tener registros que queden en null debido a que esa clase no tiene el atributo (Como el caso del 'salario' en Pasante, o 'tutor' en Contratado).
Además, la tabla de la superclase tiene una relación 'one to one' con las tablas de las subclases, ya que el ID de 'Pasante' y 'Contratado' es a su vez PK de la misma tabla y FK a un registro de la tabla 'Empleado'. Esto nos permite hacer el join entre ambas tablas y poder obtener los objetos completos.
En la creación de las tablas, primero se crea cada tabla por separado, y luego se agregan las constraint de FK en las tablas 'pasante' y 'contratado'.
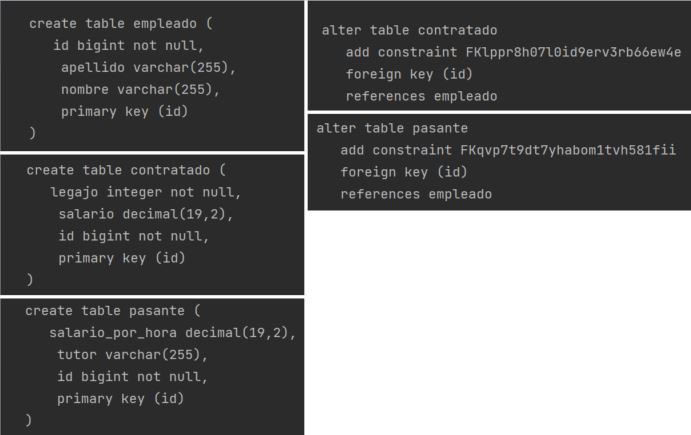
Para insertar un registro, tenemos como desventaja que necesitamos hacer 2 insert. Primero para insertar en la tabla de la superclase y luego otro insert para la tabla de la subclase. Por ejemplo, si insertamos un 'Contratado'. Esto puede ser menos performante que otra estrategia, si necesitamos hacer insert masivos, ya que vamos a tener el doble de inserciones en la base de datos.

En cuanto a las consultas, si queremos realizar una consulta polimórfica para obtener objetos de tipo Empleado, la consulta se pone un poco mas compleja respecto a la estrategia SINGLE_TABLE, ya que necesitamos un CASE para determinar si alguno de los IDs no es nulo, y en base a esa evaluación le asigna un numero, y a ese numero lo utiliza para hacer un LEFT JOIN contra todas las tablas de que representan a las subclases, de esta manera es como puede completar los campos faltantes y poder retornar un registro para un objeto de tipo Empleado.
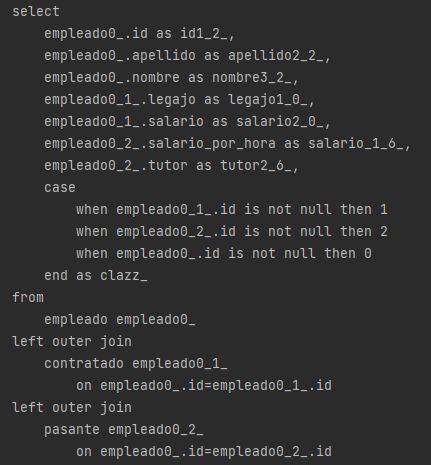
Si la consulta no es polimórfica, y por ejemplo queremos obtener un objeto de tipo Contratado, la query obtiene el registro de la subclase y realiza un JOIN contra la tabla que representa la superclase. Como vemos, realizar una consulta no polimórfica es mas eficiente que realizar una polimórfica, ya que realiza un solo JOIN contra una tabla, y no N LEFT JOIN contra las tablas "hijas" como sucede con las consultas polimórficas.
TABLE_PER_CLASS
Se genera una tabla por cada subclase de la jerarquía, repitiendo los atributos de la superclase, en cada tabla que representan a las subclases.
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public abstract class Empleado {
@Id
@GeneratedValue
private Long id;
private String nombre;
private String apellido;
}
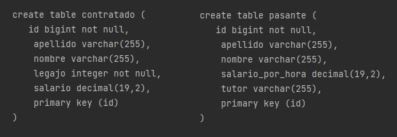
El esquema de base de datos, nos queda solo con dos tablas, una por cada clase concreta, en este caso, la tabla 'contratado' y 'pasante', con los campos propios de cada una y los campos en común.

La creación de las tablas es directa, siendo mas eficiente que la estrategia JOIN, ya que solo crea ambas tablas sin ningún otra relación con la jerarquía.
Al igual que la creación, la inserción de registros también se hace de manera directa sobre cada tabla. El problema es, que al no tener una tabla de referencia que genere los IDs (Como en el caso de la superclase en JOINED), los IDs de los registros en cada tabla se van a repetir y eso nos va a traer un problema al momento de obtener los objetos. Por ejemplo, vamos a tener un registro en 'contratado' con ID = 1, y también vamos a tener un registro en 'pasante' con ID = 1. Por tal motivo, tenemos que indicarle al ORM que utilice una estrategia para generar los ID en la superclase, por ejemplo, en la clase abstracta Empleado vamos a tener:
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;
En cuanto a las consultas polimórficas, son las mas costosas entre las 3 estrategias, ya que en el FROM debe generar una UNION entre ambas tablas y ésta operación es menos eficiente que el JOIN, teniendo en cuenta que a mayor cantidad de tablas, mayor va a ser la cantidad de uniones que deba realizar.
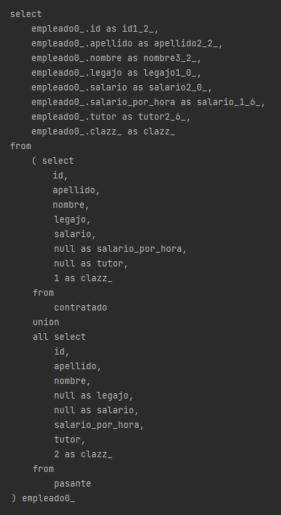
Las consultas no polimórficas, se vuelven mas eficientes ya que se ejecutan sobre una sola tabla.
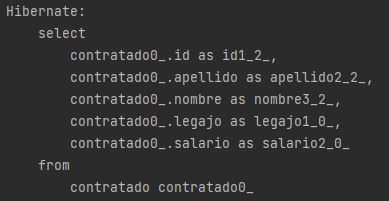
En caso de que otra clase tenga un atributo de tipo Empleado, con esta estrategia perdemos la integridad referencial, es decir que no podemos poner FK contra los IDs de 'Contratado' y 'Pasante', ya que no sabemos contra cual de las dos tablas específicamente nos estamos relacionando.
Veamos esto en un simple ejemplo para entenderlo mejor. Tenemos una relación @OneToOne entre Proyecto y Empleado.
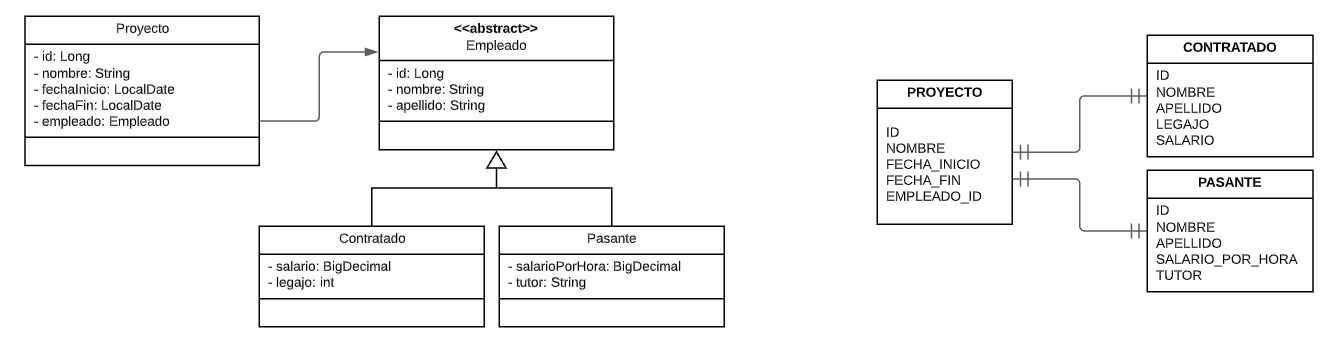
En este caso, el campo EMPLEADO_ID no podría ser FK al ID de las tablas con las que se relaciona, ya que en la misma definición de la FK, no se podría determinar sobre que tabla es. Por lo tanto estamos perdiendo una poderosa herramienta que nos brinda el motor de base de datos, que es la integridad referencial.
RESUMIENDO
Ahora que ya sabemos como funciona cada estrategia, y que ventajas y desventajas nos puede traer, podemos resumir que características tenemos a favor y en contra.
| Estrategia | A favor | En contra |
| SINGLE_TABLE | - Es mas simple - Buena performance en general - Evita generar muchas tablas |
- Los campos no utilizados deben aceptar valores nulos - Puede generar confusión para entender el dominio si ves solo la tabla - Necesita un campo discriminador para generar los objetos |
| JOINED | - Cumple con las formas normales - Admite campos no nulos para cada subclase - No requiere de un campo discriminador - Soporta todo tipo de relaciones polimórficas |
- Es la estrategia que mas entidades requiere crear - Es la estrategia que mas accesos a la base de datos requiere |
| TABLE_PER_CLASS | - Permite campos no nulos para cada subclase - No requiere de un campo discriminador |
- Para consultas polimórficas requiere de uniones que pueden disminuir la performance - Perdemos integridad referencial en relaciones *toOne - Las subclases repiten atributos heredados de la superclase |